12 Confidence intervals
2.0
Functions introduced in this chapter
get_confidence_interval, shade_confidence_interval, fct_collapse
12.1 Introduction
Sampling variability means that we can never trust a single sample to identify a population parameter exactly. Instead of simply trusting a point estimate, we can look at the entire sampling distribution to create an interval of plausible values called a confidence interval. By making our intervals wide enough, we hope to have some chance of capturing the true population value. Like hypothesis tests, confidence intervals are a form of inference because they use a sample to deduce something about the population. Along the way, we will also learn about a new form of randomization called bootstrapping.
12.1.2 Download the R notebook file
Check the upper-right corner in RStudio to make sure you’re in your intro_stats project. Then click on the following link to download this chapter as an R notebook file (.Rmd).
https://vectorposse.github.io/intro_stats/chapter_downloads/12-confidence_intervals.Rmd
Once the file is downloaded, move it to your project folder in RStudio and open it there.
12.2 Load packages
We load the standard tidyverse, janitor, and infer packages. We’ll also need the openintro package later in the chapter for the hsb2 and the smoking data set.
## ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
## ✔ dplyr 1.1.2 ✔ readr 2.1.4
## ✔ forcats 1.0.0 ✔ stringr 1.5.0
## ✔ ggplot2 3.4.2 ✔ tibble 3.2.1
## ✔ lubridate 1.9.2 ✔ tidyr 1.3.0
## ✔ purrr 1.0.2
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors##
## Attaching package: 'janitor'
##
## The following objects are masked from 'package:stats':
##
## chisq.test, fisher.test## Loading required package: airports
## Loading required package: cherryblossom
## Loading required package: usdata12.3 Bootstrapping
Imagine you obtain a random sample of 200 high school seniors from across the U.S. Suppose 32 of them attend private school. As a sample statistic, we have
\[ \hat{p} = 32/200 = 0.16 \] In other words, 16% of the students in the sample attended private school.
If our sample is representative, we might guess that the true population parameter \(p\) is also close to 0.16, but we’re not really sure:
\[ p \approx 0.16? \]
And what about the sampling variability? A few chapters ago, we flipped coins. A “weighted” coin flipped 200 times can give us a “new” (fake) sample, and doing that a thousand times (or even more) can give us a lot of new samples to see what range of values is possible. But what would we use as the probability of heads for the weighted coin? It would be a bad idea to use 0.16 because that would assume that the population proportion agreed exactly with the one sample we happen to have. It worked in a hypothesis test because we had a value of \(p\) we assumed was true in the guise of a null hypothesis. But in general, if I simply want to estimate a population parameter with a sample statistic, I have no such information to use. So coin flipping is out.
An alternative that is available to us is a procedure called bootstrapping. The idea sounds weird, but it’s pretty simple: instead of building fake samples, what if we tried to build a fake population? And then, what if we took repeated samples from it?
How would we build a fake population? Imagine making many, many copies of our sample until we had thousands or even millions of students. In fact, we can think of an infinite number of copies of our sample if we want. Sure, this fake population isn’t exactly like the real population of all high school seniors. But if our sample is representative, we might hope that lots of copies of our sample would approximate the population we care about.
Computationally, it’s a lot of work to copy our sample thousands or millions of times. And we certainly can’t work with an infinite number of copies. Fortunately, we can use a shortcut. It’s called sampling with replacement.
Normal sampling is usually without replacement, meaning that once we have sampled an individual, they are not eligible to be sampled again. We don’t want to survey Billy and then later in our study, survey Billy again.
In sampling with replacement, we put Billy back in the pool and make him eligible to be sampled again. This is the same thing as having access to an infinite population. Remember that our fake population is just many, many copies of our sample. So in that fake population, there are many, many Billy clones that could end up in our sample. So rather than cloning Billy many, many times, let’s just put Billy back in the group any time he’s sampled.
We need to see this in action. We have a random sample of 200 students obtained by the National Center of Education Statistics in their “High School and Beyond” survey. This is stored in the hsb2 data set from the openintro package. Here are the school types for these students, stored in the variable schtyp:
hsb2$schtyp## [1] public public public public public public public public public
## [10] public public public public public public public public private
## [19] public public public public public public public public public
## [28] private private public public public private public private public
## [37] private public public public private private public public public
## [46] public public public private public public public public private
## [55] public public public public private public private public public
## [64] public private public public public public public public public
## [73] public public public public public public public public public
## [82] public private public public public public public public public
## [91] public public public public public public public public public
## [100] private public public public public public public public public
## [109] private private public public public public private public public
## [118] public public public private public public public public public
## [127] public public public public public public public public public
## [136] public private public public private public public public public
## [145] public private public private public public public public public
## [154] public public public public public public public public public
## [163] private public public public public public private public public
## [172] public public public public public public public public public
## [181] public private public public public public public public private
## [190] public public private private public private private public private
## [199] public public
## Levels: public privateLet’s sample an individual from our sample:
## [1] public
## Levels: public privateThat was one of the public school students from among the 200 students in our sample. Here’s another one:
## [1] private
## Levels: public privateThat was one of the private school students.
We can do this 200 times. Now, if we sample without replacement, all we get back are the original students, just listed in a different order. Think about why: we’re just picking one student at a time. But since they don’t get replaced, eventually, every student will get chosen. We’re choosing 200 students, but there are only 200 students from which to choose.
set.seed(8)
sample_without_replacement1 <- sample(hsb2$schtyp, size = 200)
sample_without_replacement1## [1] public public public public public public public public public
## [10] public public public public public public public private public
## [19] public public public public public public public public public
## [28] public public private public public public public public public
## [37] public public public public public public public private public
## [46] public public public public private private private public public
## [55] private private public public public public public public private
## [64] public public private public public public public public public
## [73] public public public public public public public public public
## [82] public public public public public public public public public
## [91] public public public public public public public public public
## [100] public public private public public public public public public
## [109] public public public public public public public public public
## [118] public public public private public public private public public
## [127] private private public public public public private public private
## [136] private public public public public public public public public
## [145] public public public public public public public public private
## [154] public public public public public private public private private
## [163] public public public public private public public private public
## [172] private private public public public public public public public
## [181] public private public private public public public private private
## [190] public public public public public public public public private
## [199] public private
## Levels: public private
tabyl(sample_without_replacement1)
set.seed(9)
sample_without_replacement2 <- sample(hsb2$schtyp, size = 200)
sample_without_replacement2## [1] public public public private public private public private public
## [10] public public private private private private private public public
## [19] private public public public public public public public public
## [28] public public public public public public public public public
## [37] public public public public public public public private public
## [46] public public public public private public private public public
## [55] public private public public public public public public public
## [64] private public public public public public public public public
## [73] public public public public private public public public public
## [82] private private public public public public public public private
## [91] public private public public public private public public public
## [100] public public private private public public public public public
## [109] public private public public private public private public public
## [118] public public public public public private public public public
## [127] public public public public public public public public public
## [136] public public public public public public private public public
## [145] public private public public public public public public public
## [154] public public public public public public public public private
## [163] private public public public public public public public public
## [172] public public public public public public public public public
## [181] private public public public public public private public public
## [190] public public public public public public public public public
## [199] public public
## Levels: public private
tabyl(sample_without_replacement2)The two lists above consist of the same 200 students, just drawn in a different order.
On the other hand, if we sample with replacement, then students can get chosen more than once. (Remember, we’re equating “getting chosen more than once” with “sampling from an infinite population and choosing a clone”.) Now, the number of private school students we see might not be 32.
Each of the following samples is called a bootstrap sample. Notice that we’ve added the argument replace = TRUE to the sample function:
set.seed(10)
sample_with_replacement1 <- sample(hsb2$schtyp, size = 200, replace = TRUE)
sample_with_replacement1## [1] private public public public public private public public public
## [10] public public public public public public public public public
## [19] private public public public public private private private public
## [28] public private public public public private public public public
## [37] public public public public public public private public public
## [46] public public public public public public private public public
## [55] public public public public public public public public public
## [64] public public private public private public public public private
## [73] public public public public public public public public public
## [82] public public public public private public public public public
## [91] public private public private public private public public public
## [100] public public public private private public public public public
## [109] public public public public public private private public public
## [118] private public public private public public private public public
## [127] public public public private private private public public private
## [136] public public public public public public public public public
## [145] public public public public public public public public public
## [154] public public public public public public public private public
## [163] public public public private private public private private private
## [172] public public public public public public private public public
## [181] public public public public public public private public public
## [190] public public public public public public public public public
## [199] public public
## Levels: public private
tabyl(sample_with_replacement1)That bootstrap sample proportion is 0.18, not 0.16.
set.seed(11)
sample_with_replacement2 <- sample(hsb2$schtyp, size = 200, replace = TRUE)
sample_with_replacement2## [1] public public public public public private public public private
## [10] public public private public public public public public public
## [19] public public public public public public public public public
## [28] public public public public public public public public public
## [37] public public public public public public public public public
## [46] public public public public public public public private public
## [55] public public public public public public public public public
## [64] public public public public public public public public public
## [73] public public public public private public public public public
## [82] public private private public public private public public public
## [91] public private public public public public private public private
## [100] public public private public public public public public public
## [109] public public private public public private public public public
## [118] private private public public public public private public private
## [127] public private public private public public public private public
## [136] private public public public private private private public private
## [145] public public private public public private public public public
## [154] private private public public public public public public private
## [163] private public public public public public private public private
## [172] public public public private private public private public public
## [181] public public public public public public public public public
## [190] public private public private public public public private public
## [199] public public
## Levels: public private
tabyl(sample_with_replacement2)That bootstrap sample proportion is 0.2.
Now we’re getting some sampling variability!
If we do this many, many times, we get a whole collection of sample proportions. The distribution of all those sample proportions, obtained with bootstrap samples (samples drawn with replacement), is called the bootstrap sampling distribution.
12.4 Computing a bootstrap sampling distribution
The infer package can compute bootstrap samples and, hence, produce a bootstrap sampling distribution. The code looks a whole like the code you already know for hypothesis testing:
private_boot <- hsb2 %>%
specify(response = schtyp, success = "private") %>%
generate(reps = 1000, type = "bootstrap") %>%
calculate(stat = "prop")
private_bootWe simply changed the type to “bootstrap”.
Now we visualize like normal:
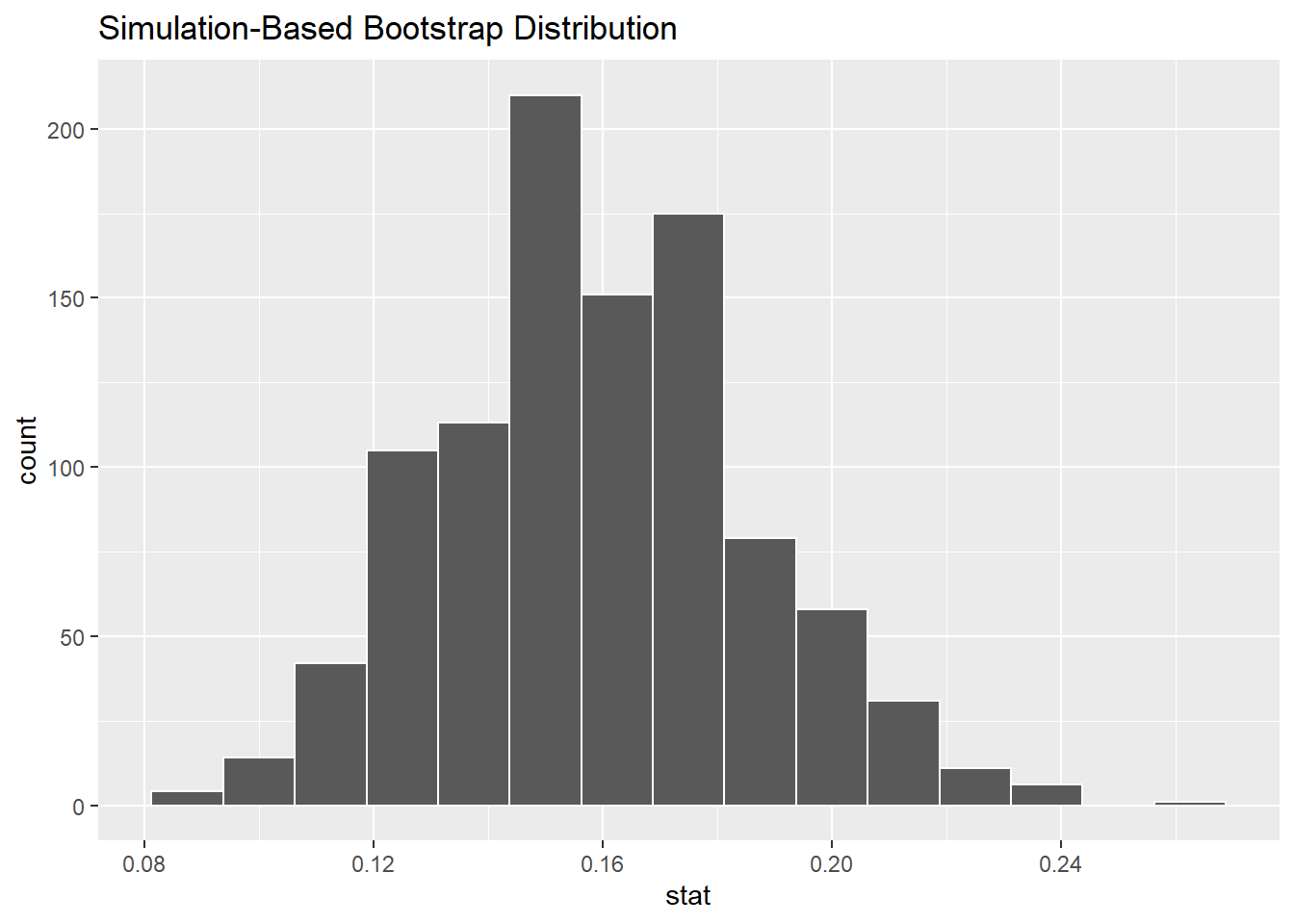
(We can change the number of bins if we want, but this number looks pretty good.)
12.5 Confidence intervals
The histogram above simulates what might happen if we took many samples from our infinite “fake” population consisting of many copies of our original, actual sample data. On the lower end, we might see something like 8% private school students. On the upper end, we could see 25% or more private school students.
In the chapter about numerical data, we computed the IQR (interquartile range), which was the difference between the 25th percentile and the 75th percentile. The IQR was then the range of the middle 50% of the data. Let’s use infer tools to calculate the middle 50% of the above distribution:
private_50 <- private_boot %>%
get_confidence_interval(level = 0.5)
private_50The middle 50% ranges from 14% up to 17.5%. We can also visualize this:
private_boot %>%
visualise() +
shade_confidence_interval(endpoints = private_50)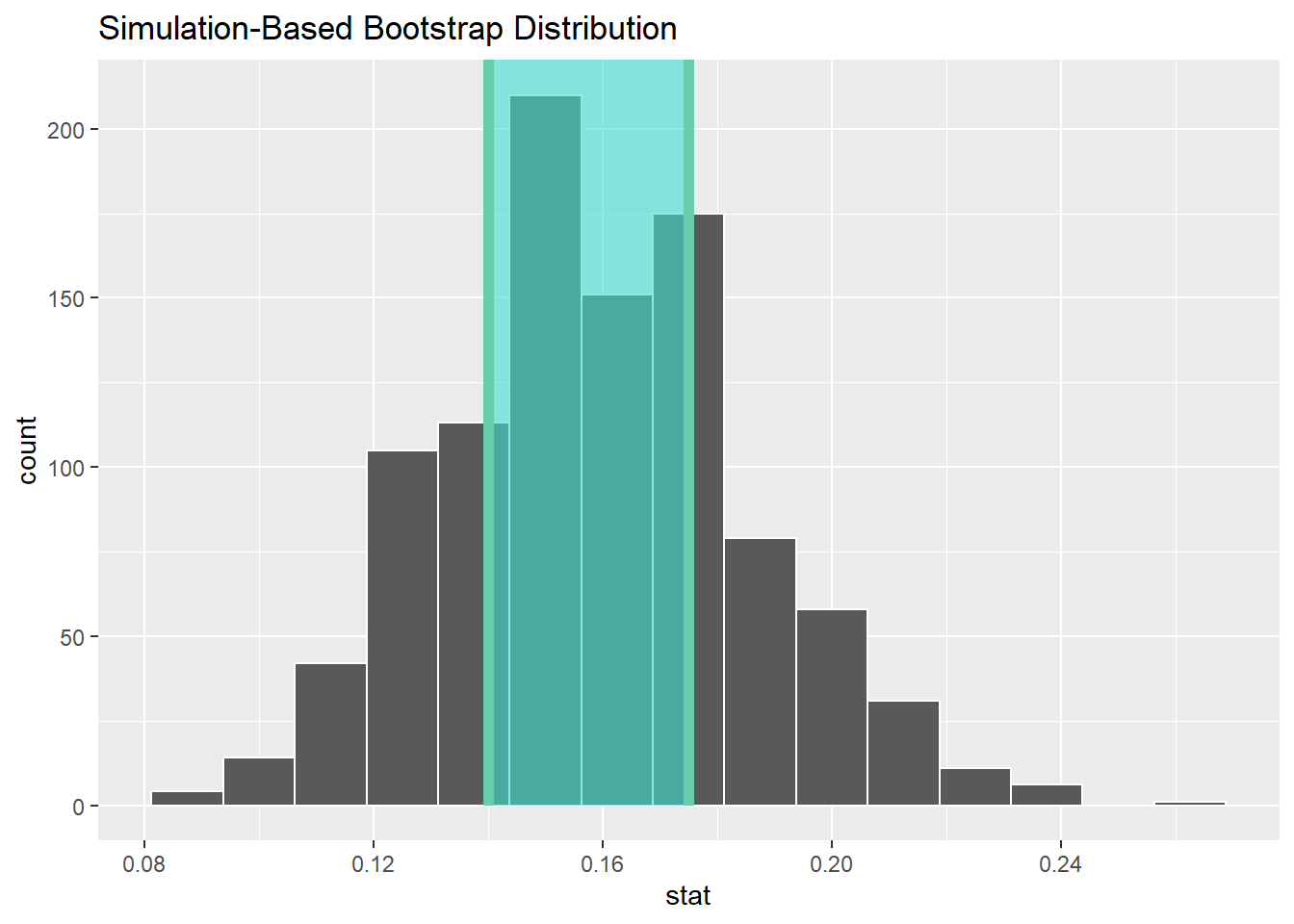
In other words, when we go out to gather a sample from our (fake infinite) population of high school seniors, about half of the time, we expect the percentage of private students to be somewhere between 14% and 17.5%. The other half of the time, we will sample a value outside that range.
This is a confidence interval. More specifically, this is a 50% confidence interval. This is the range of values we expect sample proportions to be in approximately half of the samples we might gather from our (fake infinite) population.
Now don’t forget the goal. What we are really trying to find is the value \(p\), the true population parameter. We want to know what proportion of high school seniors attend private school in the whole population of all high school seniors in the U.S.
For mathematical reasons that are outside the scope of this course, it turns out that the sampling variability in the bootstrap distribution around \(\hat{p}\) is very similar to the sampling variability of the sample proportion \(\hat{p}\) around the true value \(p\). We bootstrapped our way to the picture above using one actual sample with about 16% private school students. A different sample of high school seniors would give us different bootstrap samples, producing a slightly different bootstrap distribution from the one above. But it, too, will have a shaded region like the histogram above. Every actual sample we might obtain in the real world would give us a bootstrap distribution with a different shaded region. But the amazing fact is this: about half of those shaded regions will actually contain the true population parameter \(p\).
Think about the value \(p\) like a fish hidden in a murky lake. The sample proportion \(\hat{p}\) is our attempt at fishing. We drop a hook down at the value \(\hat{p}\) and pull it right back up. It’s not very likely that we caught the fish, although we hope that we were close. Alas, the sample proportion is almost never exactly equal to the true proportion \(p\). But what if we cast a net instead? That net is the shaded range of values in our confidence interval. That range of values might catch the fish.
The difference between statistics and fishing is that, in the latter, when we pull up the net, we can see if we successfully caught the fish. In the former, all we can say is that there is some probability that the net caught the fish, but you’re not able to look inside the net to know for sure.
So the confidence interval we created above might have caught the true value \(p\). But then again, it might not have. There’s only a 50% chance we captured the true value in the range 14% to 17.5% that we computed from our specific sample with its accompanying bootstrap samples. Most researchers would be displeased with only a 50% success rate. So can we do better?
How much better do we want to do? This is a subjective question with no definitive answer. Many people say they want to be 95% confident that the confidence interval they build will capture the true population parameter. Let’s modify our code to do that:
private_95 <- private_boot %>%
get_confidence_interval(level = 0.95)
private_95The middle 95% ranges from 11% up to 21.5%. We can also visualize this:
private_boot %>%
visualise() +
shade_confidence_interval(endpoints = private_95)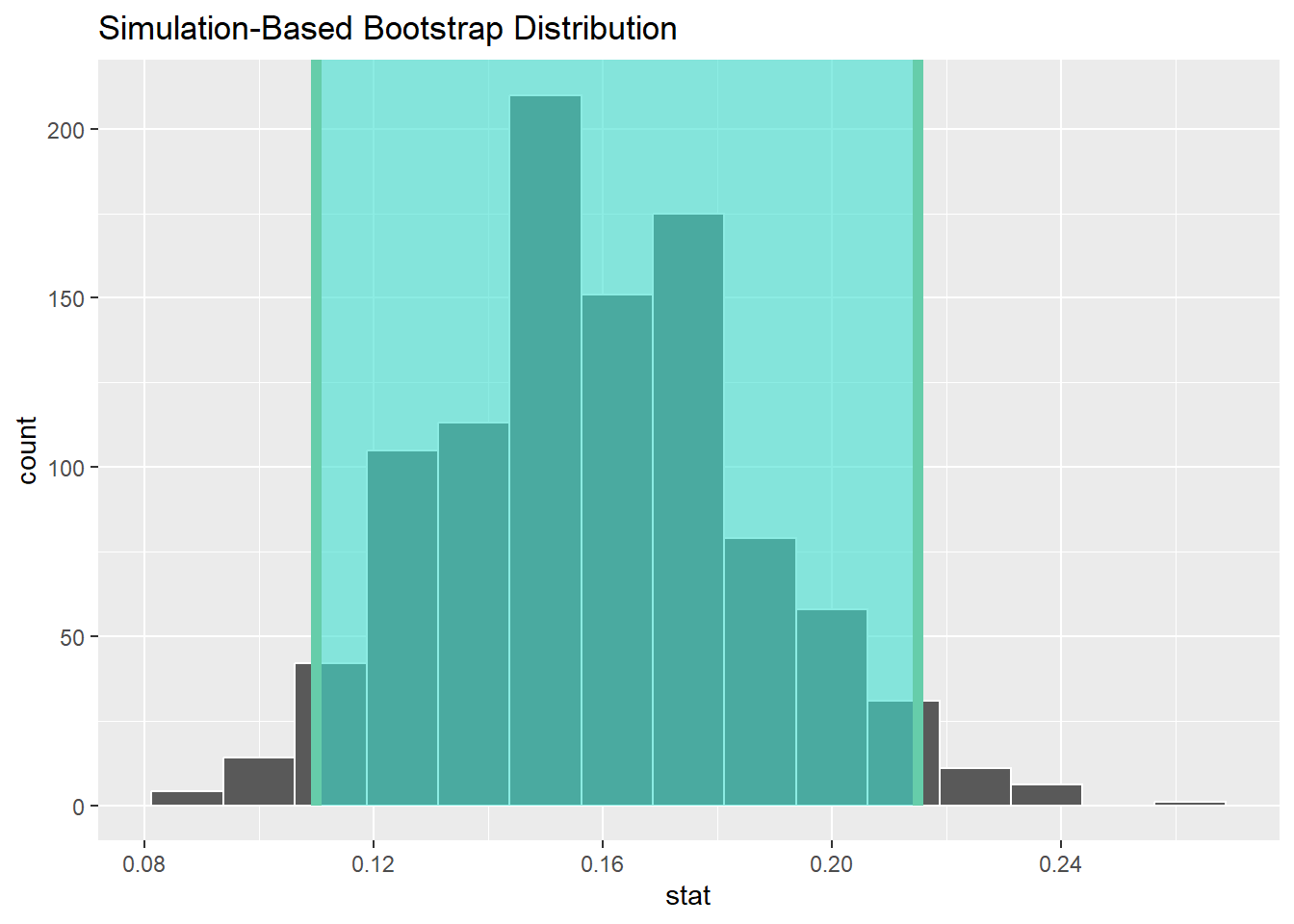
The interpretation is that when you go collect many samples, the confidence intervals you produce using the bootstrap procedure described above will capture the true population proportion 95% of the time.
Exercise 1
Why is a 95% confidence interval wider than a 50% confidence interval? In other words, why should our desire to be 95% confident in capturing the true value of \(p\) result in an interval that is wider than if we only wanted to be 50% confident?
Please write up your answer here.
Exercise 2
Being more confident seems like a good thing. In fact, we might want a 99% confidence interval. Compute and visualize a 99% confidence interval for proportion of private school students.
# Add code here to compute a 99% confidence interval
# Add code here to visualize a 99% confidence intervalExercise 3
Can you think of any downside to using higher and higher confidence levels? As a hint, think about the following completely true sentence: “I am 100% confident that the true proportion of high school seniors attending private school is somewhere between 0% and 100%.”
Please write up your answer here.
While 50% is clearly too low for a confidence level, as seen above, there is no particular reason that we need to compute a 95% confidence interval either. There is some consensus in the scientific community here: 95% has evolved to become a generally agreed-upon standard. But we could compute a 90% confidence interval or a 99% confidence interval (as you did above), or any other type of interval. Having said that, if you choose other intervals besides these three, people might wonder if you’re up to something.15
12.6 Conditions
Don’t forget that there are always assumptions we make when relying on any kind of statistical inference. Before computing a confidence interval for a proportion, we must verify that certain conditions are satisfied. But these conditions are not new. We already know from hypothesis testing what is required for good inference from a sample. These are the “Random” and the “10%” conditions.
- Random
- The sample must be random (or hopefully representative).
- 10%
- The sample size must be less than 10% of the size of the population.
Both conditions are met for the data in the High School and Beyond survey.
12.7 Rubric for confidence intervals
Typically, you will be asked to report a confidence interval after performing a hypothesis test. Whereas a hypothesis test gives you a “decision criterion” (using data to make a decision to reject the null or fail to reject the null), a confidence interval gives you an estimate of the “effect size” (a range of plausible values for the population parameter).
As such, there is a section in the Rubric for inference that shows the steps of calculating and reporting a confidence interval. They are as follows:
- Check the relevant conditions to ensure that model assumptions are met.
- Calculate and graph the confidence interval.
- State (but do not overstate) a contextually meaningful interpretation.
- If running a two-sided test, explain how the confidence interval reinforces the conclusion of the hypothesis test.
- When comparing two groups, comment on the effect size and the practical significance of the result.
12.8 Example
Here is a worked example. (Unless otherwise stated, we always use a 95% confidence level.)
Some of the students in the “High School and Beyond” survey attended vocational programs. This data is stored in the prog variable. Using a confidence interval, estimate what percentage of all high school seniors attend vocational programs.
We will need to do a little data cleaning before we can address this question. There are actually three types of programs: “general”, “academic”, and “vocational”. The infer commands will only work when a categorical variable has two levels. We are thinking of “general” and “academic” together as more like a combined “other” category. We can fix this by creating a new factor variable with mutate. Inside that mutate, we will use the fct_collapse function to collapse two of the levels into one as follows:
hsb2 <- hsb2 %>%
mutate(prog2 = fct_collapse(prog,
vocational = "vocational",
other = c("general", "academic")))
glimpse(hsb2)## Rows: 200
## Columns: 12
## $ id <int> 70, 121, 86, 141, 172, 113, 50, 11, 84, 48, 75, 60, 95, 104, 3…
## $ gender <chr> "male", "female", "male", "male", "male", "male", "male", "mal…
## $ race <chr> "white", "white", "white", "white", "white", "white", "african…
## $ ses <fct> low, middle, high, high, middle, middle, middle, middle, middl…
## $ schtyp <fct> public, public, public, public, public, public, public, public…
## $ prog <fct> general, vocational, general, vocational, academic, academic, …
## $ read <int> 57, 68, 44, 63, 47, 44, 50, 34, 63, 57, 60, 57, 73, 54, 45, 42…
## $ write <int> 52, 59, 33, 44, 52, 52, 59, 46, 57, 55, 46, 65, 60, 63, 57, 49…
## $ math <int> 41, 53, 54, 47, 57, 51, 42, 45, 54, 52, 51, 51, 71, 57, 50, 43…
## $ science <int> 47, 63, 58, 53, 53, 63, 53, 39, 58, 50, 53, 63, 61, 55, 31, 50…
## $ socst <int> 57, 61, 31, 56, 61, 61, 61, 36, 51, 51, 61, 61, 71, 46, 56, 56…
## $ prog2 <fct> other, vocational, other, vocational, other, other, other, oth…Inspect the variables prog and prog2 above to make sure that the recoding was successful. Then be sure to use prog2 and not prog everywhere.
12.8.1 Check the relevant conditions to ensure that model assumptions are met.
- Random
- The sample is a random sample of high school seniors from the U.S. as the survey was conducted by the National Center of Education Statistics, a reputable government organization.
- 10%
- The sample size is 200, which is much less than 10% of the population of all U.S. high school seniors.
12.8.2 Calculate and graph the confidence interval.
vocational_boot <- hsb2 %>%
specify(response = prog2, success = "vocational") %>%
generate(reps = 1000, type = "bootstrap") %>%
calculate(stat = "prop")
vocational_boot
vocational_ci <- vocational_boot %>%
get_confidence_interval(level = 0.95)
vocational_ci
vocational_boot %>%
visualize() +
shade_confidence_interval(endpoints = vocational_ci)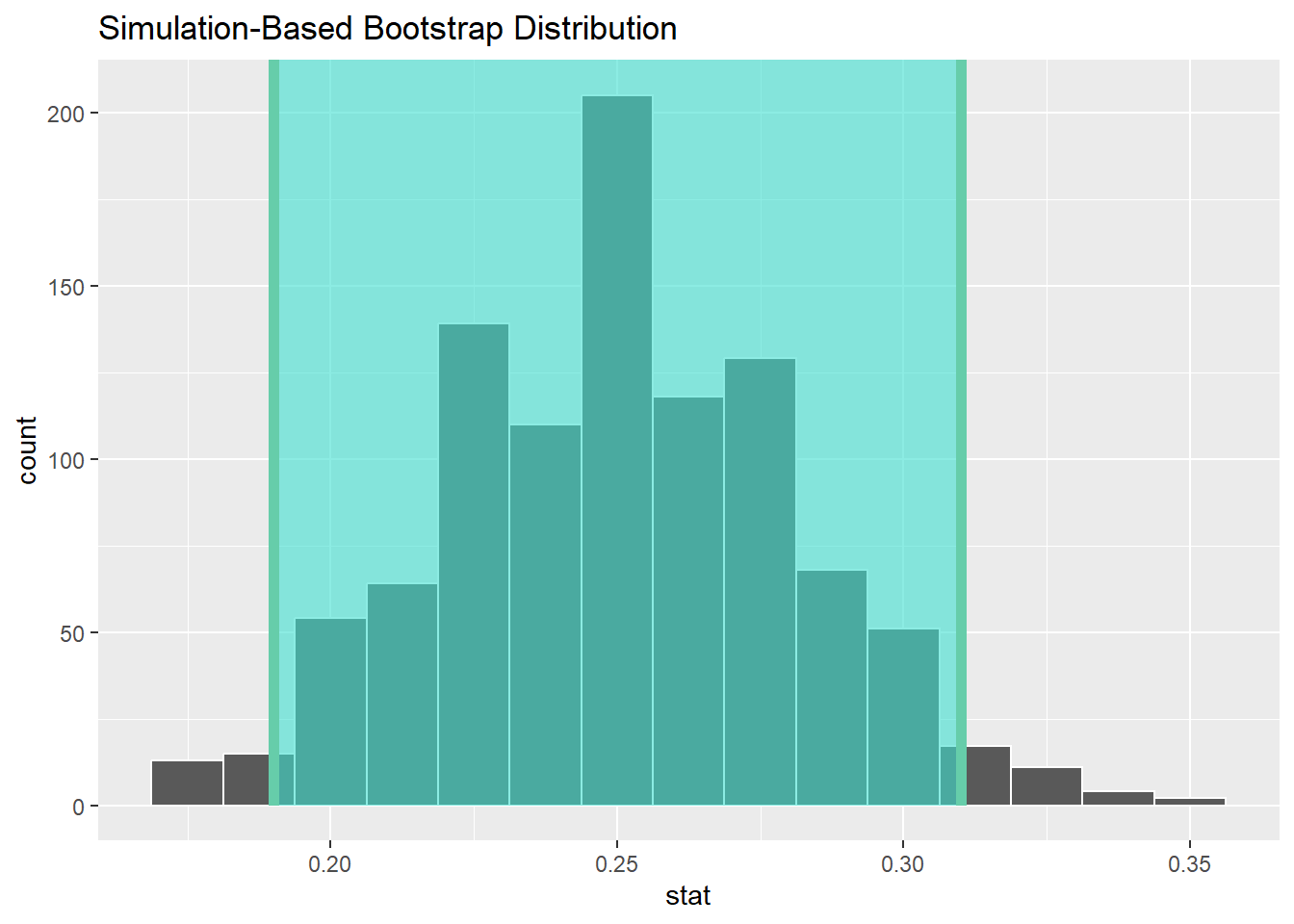
12.8.3 State (but do not overstate) a contextually meaningful interpretation.
We are 95% confident that the true percentage of U.S. high school seniors who attend a vocational program is captured in the interval (19%, 31%).
Note: we use inline code to grab the values of the endpoints of the confidence interval. We also multiply by 100 to report percentages instead of proportions.
12.8.4 If running a two-sided test, explain how the confidence interval reinforces the conclusion of the hypothesis test.
In this chapter, we haven’t run a hypothesis test, so this step is irrelevant for us here. However, in future chapters, we will incorporate this step into the rubric and see how the confidence interval relates to the conclusion of a hypothesis test.
12.8.5 When comparing two groups, comment on the effect size and the practical significance of the result.
This step will also become more clear in future chapters. It only applies to situations where you are attempting to find a difference between two groups. In this example, we’re simply using a sample statistic to estimate a single population parameter.
12.9 Your turn
Use the smoking data set from the openintro package. What percentage of the population of the U.K. smokes tobacco? (The information you need is in the smoke variable.) Use a 95% confidence interval.
Check the relevant conditions to ensure that model assumptions are met.
- Random
- [Check condition here.]
- 10%
- [Check condition here.]
12.10 Interpreting confidence intervals
Confidence intervals are notoriously difficult to interpret.16
Here are several wrong interpretations of a 95% confidence interval:
95% of the data lies in the interval.
There is a 95% chance that the sample proportion lies in the interval.
There is a 95% chance that the population parameter lies in the interval.
We’ll take a closer look at these incorrect claims in a moment. First, let’s see how confidence intervals work using simulation.
In order to simulate, we’ll have to pretend temporarily that we know a true population parameter. Let’s use the example of a candidate who has the support of 64% of voters. In other words, \(p = 0.64\). We go out and get a sample of voters, let’s say 50. From that sample we construct a 95% confidence interval by bootstrapping. Most of the time, 64% (the true value!) should be in our interval. But sometimes it won’t be. We can get an unusual sample that is far away from 64%, just by pure chance alone. (Perhaps we accidentally run into a bunch of people who oppose our candidate.)
Okay, let’s do it again. Get a new sample and calculate a new confidence interval. This sample will likely result in a different sample proportion than the first sample. Therefore, the confidence interval will be located in a different place. Does it contain 64%? Most of the time, we expect it to. Occasionally, it will not.
We can do this over and over again through the magic of simulation! Here’s what this simulation looks like in R. The following code is quite technical, although you will recognize bits and pieces of it. Don’t worry about it. You won’t need to generate code like this on your own. Just look at the pretty picture in the output below below the code.
set.seed(11111)
# The true population proportion is 0.64
true_val <- 0.64
# The sample size is 50
sample_size <- 50
# Set confidence level
our_level <- 0.95
# Set number of intervals to simulate
sim_num <- 100
# Get a random sample of size n.
# Compute the test statistic and the bootstrap confidence interval.
# Put both into a single tibble.
simulate_ci <- function(n, level = 0.95) {
sample_data <-
factor(rbinom(n , size = 1, prob = true_val)) %>%
tibble(data = .)
stat <- sample_data %>%
observe(response = data, success = "1", stat = "prop")
ci <- sample_data %>%
specify(response = data, success = "1") %>%
generate(reps = 1000, type = "bootstrap") %>%
calculate(stat = "prop") %>%
get_confidence_interval(level = our_level)
bind_cols(stat, ci) %>%
return()
}
# Simulate 100 random samples (each of size 50)
# Assign a color based on whether the intervals contain the true proportion
ci <- map_dfr(rep(sample_size, times = sim_num), simulate_ci, level = our_level) %>%
mutate(row_num = row_number()) %>%
mutate(color = ifelse(lower_ci <= true_val & true_val <= upper_ci,
"black", "red"),
alpha = ifelse(color == "black", 0.5, 1))
# Plot all the simulated intervals
ggplot(ci, aes(x = stat, y = row_num,
color = color, alpha = alpha)) +
geom_point() +
scale_color_manual(values = c("black", "red"), guide = "none") +
geom_segment(aes(x = lower_ci, xend = upper_ci, yend = row_num)) +
geom_vline(xintercept = true_val, color = "blue") +
scale_alpha_identity() +
labs(y = "Simulation", x = "Estimates with confidence intervals")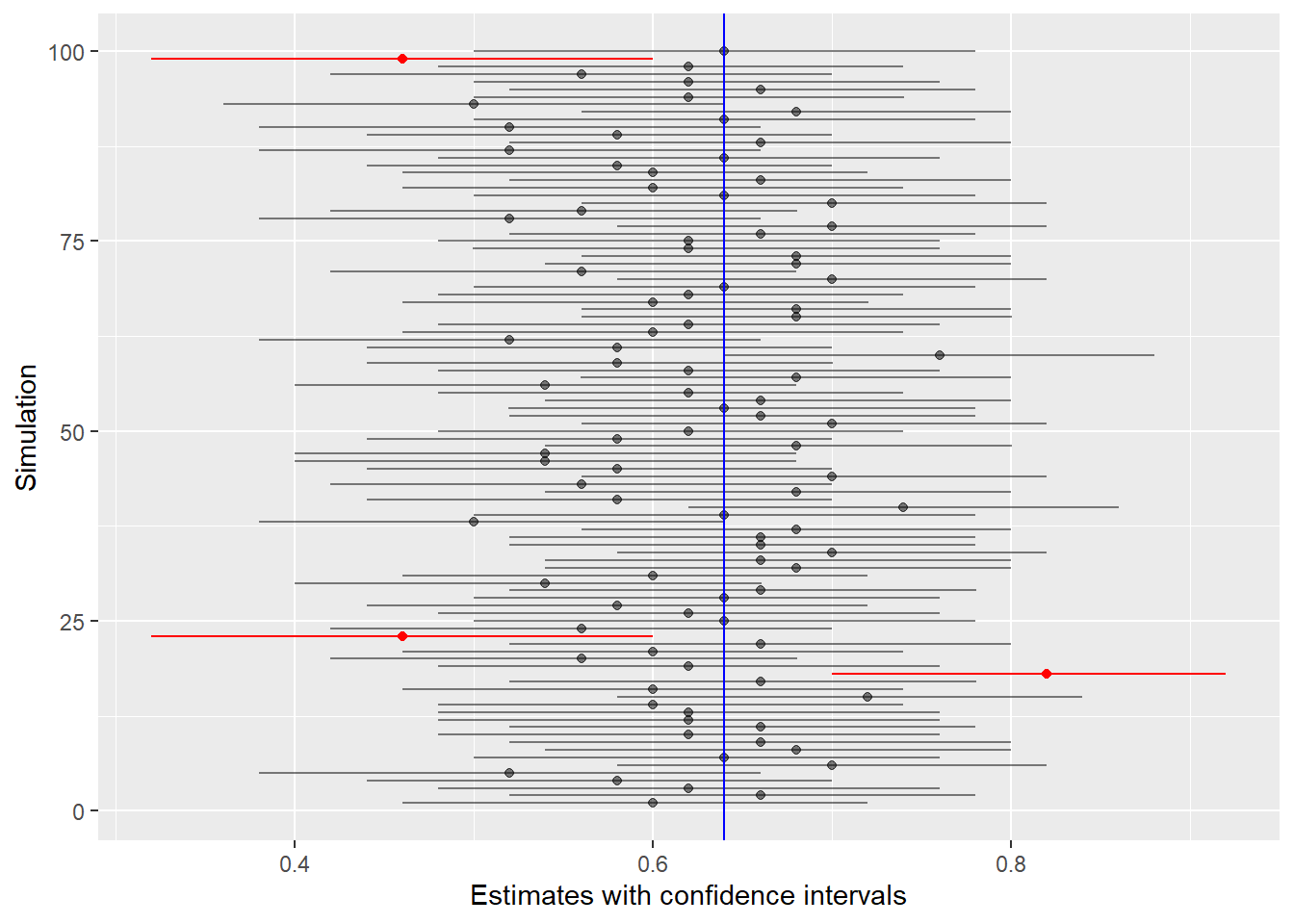
Each sample gives us a slightly different estimate, and therefore, a different confidence interval as well.
For each of the 100 simulated intervals, most of them (the black ones) do capture the true value of 0.64 (the blue vertical line). Occasionally they don’t (the red ones). We expect 5 red intervals, but since randomness is involved, it won’t necessarily be exactly 5. (Here there were only 3 bad intervals.)
This is the key to interpreting confidence intervals. The “95%” in a 95% confidence interval means that if we were to collect many random samples, about 95% of them would contain the true population parameter and about 5% would not.
So let’s revisit the erroneous statements from the beginning of this section and correct the misconceptions.
-
95% of the data lies in the interval.- This doesn’t even make sense. Our data is categorical. The confidence interval is a range of plausible values for the proportion of successes in the sample.
-
There is a 95% chance that the sample proportion lies in the interval.- No. There is essentially a 100% chance that the sample proportion lies in the interval. Most of the time, the sample proportion is very close to the center of the interval. When we bootstrap, the “infinite population” we are simulating has the same population proportion as the sample we started with. (After all, the infinite population is just many copies of the sample we started with.) Therefore, samples from that infinite population should be more or less centered around the sample proportion.
-
There is a 95% chance that the population parameter lies in the interval.- This is wrong in a more subtle way. The problem here as that it takes our interval as being fixed and special, and then tries to declare that of all possible population parameters, we have a 95% chance of the true one landing in our interval. The logic is backwards. The population parameter is the fixed truth. It doesn’t wander around and land in our interval sometimes and not at other times. It is our confidence interval that wanders; it is just one of many intervals we could have obtained from random sampling. When we say, “We are 95% confident that…,” we are just using a convenient shorthand for, “If we were to repeat the process of sampling and creating confidence intervals many times, about 95% of those times would produce an interval that happens to capture the actual population proportion.” But we’re lazy and we don’t want to say that every time.
12.11 Conclusion
A confidence interval is a form of statistical inference that gives us a range of numbers in which we hope to capture the true population parameter. Of course, we can’t be certain of that. If we repeatedly collect samples, the expectation is that 95% of those samples will produce confidence intervals that capture the true population parameter, but that also means that 5% will not. We’ll never know if our sample was one of the 95% that worked, or one of the 5% that did not. And even if we get one of the intervals that worked, all we have is a range of values and it’s impossible to determine which of those values is the true population parameter. Because it’s statistics, we just have to live with that uncertainty.
12.11.1 Preparing and submitting your assignment
- From the “Run” menu, select “Restart R and Run All Chunks”.
- Deal with any code errors that crop up. Repeat steps 1–-2 until there are no more code errors.
- Spell check your document by clicking the icon with “ABC” and a check mark.
- Hit the “Preview” button one last time to generate the final draft of the
.nb.htmlfile. - Proofread the HTML file carefully. If there are errors, go back and fix them, then repeat steps 1–5 again.
If you have completed this chapter as part of a statistics course, follow the directions you receive from your professor to submit your assignment.