2 Variance
2.1 A quick refresher on the mean
Most of us were taught how to calculate the mean of a variable way back in elementary school: add up all the numbers and divide by the size of the group of numbers. In a statistics context, we often use a “bar” to indicate the mean of a variable; in other words, if a variable is called \(X\), the mean is denoted \(\overline{X}\). Remembering that we always use \(n\) to represent the sample size, the formula is
\[ \overline{X} = \frac{\sum{X}}{n} \]
(In case you forgot, the Greek letter Sigma \(\Sigma\) stands for “sum” and means “add up all values of the thing that follows”.)
Here is a small data set we’ll use throughout this chapter as a simple example we can work “by hand”:
3, 4, 5, 6, 6, 7, 8, 9
Calculate the mean of this set of eight numbers.
2.2 Calculating variance
Variance is a quantity meant to capture information about how spread out data is.
Let’s build it up step by step.
The first thing to note about spread is that we don’t care how large or small the numbers are in any absolute sense. We only care how large or small they are relative to each other.
Look at the numbers from the earlier exercise:
3, 4, 5, 6, 6, 7, 8, 9
What if we had the following numbers instead?
1003, 1004, 1005, 1006, 1006, 1007, 1008, 1009
Explain why any reasonable measure of “spread” should be the same for both groups of numbers.
One way to measure how large or small a number is relative to the whole set is to measure the distance of each number to the mean.
Recall that the mean of the following numbers is 6:
3, 4, 5, 6, 6, 7, 8, 9
Create a new list of eight numbers that measures the distance between each of the above numbers and the mean. In other words, subtract 6 from each of the above numbers.
Some of the numbers in your new list should be negative, some should be zero, and some should be positive. Why does that make sense? In other words, what does it mean when a number is negative, zero, or positive?
If the original set of numbers is called \(X\), then what you’ve just calculated is a new list \(\left(X - \overline{X}\right)\). Let’s start organizing this into a table:
| \(X\) | \(\left(X - \overline{X}\right)\) | \(\qquad\) | \(\quad\) |
|---|---|---|---|
| 3 | -3 | ||
| 4 | -2 | ||
| 5 | -1 | ||
| 6 | 0 | ||
| 6 | 0 | ||
| 7 | 1 | ||
| 8 | 2 | ||
| 9 | 3 |
The numbers in the second columns are “deviations” from the mean.
One way you might measure “spread” is to look at the average deviation. After all, if the deviations represent the distances to the mean, a set with large spread will have large deviations and a set with small spread will have small deviations.
Go ahead and take the average (mean) of the numbers in the second column above.
Uh, oh! You should have calculated zero. Explain why you will always get zero, no matter what set of numbers you start with.
The idea of the “average deviation” seems like it should work, but it clearly doesn’t. How do we fix the idea?
Hopefully, you identified that having negative deviations was a problem because they canceled out the positive deviations. But if all the deviations were positive, that wouldn’t be an issue any more.
There are two ways of making numbers positive:
- Taking absolute values
We could just take the absolute value and make all the values positive. There are some statistical procures that do just that,2 but we’re going to take a slightly different approach…
- Squaring
If we square each value, they all become positive.
Taking the absolute value is conceptually easier, but there are some historical and mathematical reasons why squaring is a little better.3
Square each of the numbers from the second column of the table above. This will calculate a new list \(\left(X - \overline{X}\right)^{2}\)
Putting the new numbers into our previous table:
| \(X\) | \(\left(X - \overline{X}\right)\) | \(\left(X - \overline{X}\right)^{2}\) | \(\quad\) |
|---|---|---|---|
| 3 | -3 | 9 | |
| 4 | -2 | 4 | |
| 5 | -1 | 1 | |
| 6 | 0 | 0 | |
| 6 | 0 | 0 | |
| 7 | 1 | 1 | |
| 8 | 2 | 4 | |
| 9 | 3 | 9 |
Now take the average (mean) of the numbers in the third column above.
The number you got (should be 3.5) is almost what we call the variance. There’s only one more annoying wrinkle.
When you took the mean of the last column of numbers, you added them all up and divided by 8 since there are 8 numbers in the list. But for some fairly technical mathematical reasons, we actually don’t want to divide by 8. Instead, we divide by one less than that number; in other words, we divide by 7.4
Re-do the math above, but divide by 7 instead of dividing by 8.
The number you found is the variance, written as \(Var(X)\). The full formula is
\[ Var(X) = \frac{\sum{\left(X - \overline{X}\right)^{2}}}{n - 1} \]
As a one-liner, the formula may look a little intimidating, but when you break it down step by step as we did above, it’s not so bad.
Here is the full calculation in the table:
| \(X\) | \(\left(X - \overline{X}\right)\) | \(\left(X - \overline{X}\right)^{2}\) | \(\quad\) |
|---|---|---|---|
| 3 | -3 | 9 | |
| 4 | -2 | 4 | |
| 5 | -1 | 1 | |
| 6 | 0 | 0 | |
| 6 | 0 | 0 | |
| 7 | 1 | 1 | |
| 8 | 2 | 4 | |
| 9 | 3 | 9 | |
| Sum: 28 | |||
| Variance: 28/7 = \(\boxed{4}\) |
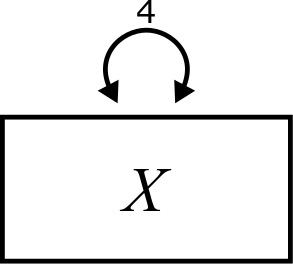
In our diagrams, the variance of a variable is indicated by a curved, double-headed arrow, labeled with the value of the variance, like this:
Using the tabular approach, calculate the variance of the following set of numbers:
4, 3, 7, 2, 9, 4, 6
Consider the following two sets of numbers:
1, 2, 5, 8, 9
1, 4, 5, 6, 9
Without doing any calculations, which of the sets has the larger variance?
Once you’ve decided, then calculate the variance for both sets and check your answer.
2.3 Calculating variance in R
Once we’ve done it by hand a few times to make sure we understand how the formula works, from here on out we can let R do the work for us:
## [1] 4## [1] 6## [1] 12.5## [1] 8.5This is also easier for real-world data that is not highly engineered 😉 to produce whole numbers:
PlantGrowth$weight## [1] 4.17 5.58 5.18 6.11 4.50 4.61 5.17 4.53 5.33 5.14 4.81 4.17 4.41 3.59 5.87
## [16] 3.83 6.03 4.89 4.32 4.69 6.31 5.12 5.54 5.50 5.37 5.29 4.92 6.15 5.80 5.26
var(PlantGrowth$weight)## [1] 0.491672.4 Variance rules
In this course, we will need to be able to calculate the variance of various combinations of variables. For example, if \(X_{1}\) and \(X_{2}\) are two variables, we can create a new variable \(X_{1} + X_{2}\) by adding up the values of the two variables. What is the variance of \(X_{1} + X_{2}\)?
But before we answer that, let’s establish the first rule.
Suppose that \(C\) is a “constant” variable, meaning that it always has the same value (rather than being a variable that could contain lots of different numbers). Then,
\[ Var\left(C\right) = 0 \]
Why is Rule 1 true? You can either reason through this conceptually, based on how you understand what variance is supposed to measure, or you can do a sample calculation. (Make a table starting with a column that contains many copies of only a single number and work through the calculation.)
Now, back to the example at the beginning of the section of finding the variance of \(X_{1} + X_{2}\).
If \(X_{1}\) and \(X_{2}\) are independent, then
\[ Var\left(X_{1} + X_{2}\right) = Var\left(X_{1}\right) + Var\left(X_{2}\right) \]
We’re not going to get into a formal definition of independence here. For now, it suffices to think of the intuitive definition you may already have in your head of what it means for two things to be independent. The idea is that, to be independent, \(X_{1}\) and \(X_{2}\) should have nothing to do with each other. Knowing a value of one variable should not give you any information about values of the other. In the next chapter, we’ll say more about this rule.
It’s important to note that Rule 2 is an abstract mathematical rule that holds in theory. When we have actual data, however, we know that statistics won’t always match their theoretical values. For example, even if a true population mean is 42, samples drawn from that population will have sample means that are close to 42, but likely not exactly 42.5
Let’s test this out. Below, we will define two new variables using random numbers.
A quick note about random numbers first: when we ask a computer to give us random numbers, it’s not going to give us truly random numbers. The algorithms are designed to give us numbers that have all the correct statistical properties of random numbers without actually being random. These are called pseudo-random numbers. We can use this fact to our benefit. The set.seed command below tells the computer to start generating numbers in a very specific way. Anyone else using R (the same version of R) who gives their machine the same “seed” will generate the same list of numbers. This makes our work “reproducible”: you will be able to reproduce the results here in this book on your own machine.
The variable X5 below is normally distributed with mean 1 and standard deviation 2. (If you don’t remember standard deviation from intro stats, we talk about it in the next section.) The next variable X6 is normally distributed with mean 4 and standard deviation 3. These are independent because the definition of X5 does not depend on any way on the definition of X6 and vice versa.
The sample sizes (2000) are large enough that we should get pretty close to the theoretically correct results here.
head(X5)## [1] -0.7535339 -0.4927789 3.7518296 1.4751639 1.2172549 3.4054426
head(X6)## [1] 2.297279 4.856377 6.661822 1.309892 2.270882 3.827944Use R to calculate the variances of X5 and X6 separately. Then use R to add the two numbers you just obtained (the sum of the two variances). Finally, use R to calculate the variance of the sum of the two variables.
Here’s an example to help think about this intuitively.
Suppose someone comes along and offers to give you a random amount of money, some number between $0 and $100.6 If the variance is a measure of spread, then it stands to reason that variance reflects something about how uncertain you are about how much money you will have after this transaction. On average, you expect about $50, but you know that the actual amount of money you will receive can vary greatly.
Okay, now a second person comes along and offers you the same deal, a random dollar gift between $0 and $100.7 At the end of both transactions, how much money will you have? On average, maybe about $100, but what about your uncertainty? Because the total amount is the result of two random gifts, you are even less sure how close to $100 you might be. The range of possible values is now $0 to $200.8 Your uncertainty is greater overall.
Of course, all this explains is why the variance of the sum of two variables is larger than the variance of either variable individually. The fact that the variance of the sum of two independent variables is exactly the sum of the variances has to be shown mathematically. But hopefully, the intuition is clear.
The next rule is a consequence of the first two rules, so we will not give it a special number
\[ Var\left(X + C\right) = Var\left(X\right) \]
Can you apply Rule 2 followed by Rule 1 to see mathematically why \(Var\left(X + C\right) = Var\left(X\right)\)?
This assumes that a constant is independent of any other variable? Intuitively speaking, why is this true?
What is the intuition behind the statement \(Var\left(X + C\right) = Var\left(X\right)\)? In other words, can you explain the rule to someone in terms of what it means about shifting the values of a data set up or down by a constant amount?
Rule 3 is similar to Rule 2, but it’s quite counter-intuitive:
If \(X_{1}\) and \(X_{2}\) are independent, then
\[ Var\left(X_{1} - X_{2}\right) = Var\left(X_{1}\right) + Var\left(X_{2}\right) \]
It is very common for students to think that a minus sign on the left would translate into a minus sign on the right.9
What gives?
Let’s return to our example of strangers giving you money.10 The first person still offers you a random amount between $0 and $100. But, now, the second person is a robber, and forces you to give them a random dollar value between $0 and $100 (of their choosing, of course). How much money do you expect to have after these two events? On average, $0. (The first person gives you, on average, $50, and the second person takes away, on average, $50.) But how certain are you about that amount?
Imagine a world in which the wrong rule prevailed. What if \(Var\left(X_{1} - X_{2}\right)\) were truly the difference of the two variances. But \(Var\left(X_{1}\right)\) and \(Var\left(X_{2}\right)\) are the same in this scenario. (Although one person is giving money and one is taking, our uncertainty about the dollar amount is the same in both cases.) And this implies \[ Var\left(X_{1}\right) - Var\left(X_{2}\right) = 0 \] Can this be true? Zero variance means “no spread” which means exact certainty of the value. (Remember Rule 1?) Are you 100% confident that you will end both transactions with exactly $0? No way!
In fact, the amount of money you end up with ranges from -$100 up to $100. This is a larger range than in either transaction individually. Our uncertainty has grown because there are two random processes in play, just like in the scenario with two beneficent strangers. In fact, the width of the range of possibilities is the same in both scenarios: $0 to $200 and -$100 to $100 both span a range of $200.
The next rule, unfortunately, does not have a great intuitive explanation. It will make a little more sense in the next chapter, and we’ll revisit it then.
If you go back to the table, imagine multiplying every number in the first column by \(a\). Every number in the second column will still have a factor of \(a\). But when you square those values, every number in the third column will have a factor of \(a^{2}\). That’s the gist of the rule anyway. But, again, there’s not much intuition about why that makes sense.
We can, at least, check empirically that the rule works.
We’ll use \(X_{5}\) as we defined it above, a normally distributed variable with mean 1 and standard deviation 2. The variance of the data is about 4:
var(X5)## [1] 4.15763Let’s use \(a = 3\).
In R, calculate \(Var\left(3X_{5}\right)\). (Don’t forget that in R, you can’t just type 3 X5. You have to explicitly include the multiplication sign: 3 * X5.)
Now try calculating \(3 Var\left(X_{5}\right)\). You’ll see that you don’t get the right answer.
But now try \(9 Var\left(X_{5}\right)\). That should work.
And that’s all the variance rules we’ll need!
2.5 Standard deviation
The variance is nice because it obeys all the above rules. The one big downside is that it’s not very interpretable.
For example, think of the scenario with people giving/taking money. In that case, the values were measures in units of dollars.
If \(X\) is measured in dollars, what are the units of measurement of \(\overline{X}\)? That seems sensible, right?
What are the units of \(\left(X - \overline{X}\right)\)? Still sensible, right? (It’s not a problem that some of these values will be positive and other negative. Negative dollars still make sense. Just think about your student loans.)
Okay, now here’s where things get weird. What are the units of \(\left(X - \overline{X}\right)^{2}\)? This no longer makes sense.
Variance is nearly the average of a bunch of squared deviations, so for a variable measured in dollars, the units of variance would be “squared dollars”, whatever that is.
Variances are not really interpretable directly. How do we make them more interpretable? Well, if variance has “squared” units, we can take the square root to get back to the natural units we started with.
And this is called the standard deviation, \(SD(X)\).
\[ SD(X) = \sqrt{\frac{\sum{\left(X - \overline{X}\right)^{2}}} {n - 1}} \]
Or, said more simply,
\[ SD(X) = \sqrt{Var(X)} \] Equivalently,
\[ Var(X) = SD(X)^2 \]
Often, if more concise notation is required, we write \(s_{X}\) for \(SD(X)\).
\[ s_{X} = \sqrt{Var(X)} \] \[ Var(X) = s_{X}^2 \]
Due to its interpretability, an intro stats class will focus far more on the standard deviation than on the variance. The downside is that the mathematical rules aren’t so nice for standard deviations. For example, what is \[ SD\left(X_{1} + X_{2}\right)? \]
You can work through the definition to see that
\[ SD\left(X_{1} + X_{2}\right) = \sqrt{ SD\left(X_{1}\right)^{2} + SD\left(X_{2}\right)^{2} } \] But, eww, that’s gross.
The constant multiple rule works out nice, though.
For any number \(a\), what is \(SD(aX)\)? Finish the following calculation until you can simplify it and get back something involving just \(SD(X)\):
\[\begin{align} SD(aX) &= \sqrt{Var(aX)} \\ &= \quad ??? \end{align}\]
Be careful! What happens if \(a\) is a negative number? Standard deviations (like variances) should always be non-negative.
A convenient way to express the fact that the coefficient will always come out positive is the following:
\[ SD(aX) = \left| a \right| SD(X) \]
For SEM, we will focus almost exclusively on variance and switch to standard deviation for only two reasons:
- We need to communicate something about spread in meaningful units.
- We need to standardize variables. (See Section 2.7 below.)
Although the standard deviance is just the square root of the variance, it is worth knowing the R command to calculate it. It’s just sd. For example:
sd(PlantGrowth$weight)## [1] 0.7011918You can see below that sd did the right thing:
## [1] 0.70119182.6 Mean centering data
Many of the statistical techniques taught in an intro stats course focus on learning about the means of variables. Structural equation modeling is a little different in that it is more focused on the explaining the variability of data—how changes in one or more variables predict changes in other variables.11
A habit we’ll start forming now is to mean center all our variables. We do this by subtracting the mean of a variable from all its values.
Let’s use \(X_{6}\) as we defined it before, a normally distributed variable with mean 4 and standard deviation 3. How do we interpret the values of \(X_{6} - \overline{X_{6}}\)? (Remember, this is just the second column in our variance tables earlier.)
If we shift all the \(X_{6}\) values to the left by \(\overline{X_{6}}\) units, what is the mean of the new list of numbers?
Let’s verify this in R. We’ll use the “suffix” mc to indicate a mean-centered variable.
## [1] 2.851573e-16Why does this answer not exactly agree with the “theoretical” answer you came up with in a few lines above? (If you don’t already know, the e-16 in the expression above is scientific notation and means “times \(10^{-16}\). That’s a really small number!)
Take a guess about the variance of X6_mc. Verify your guess in R.
So the good news is that mean centering preserves the variance. While the mean will be shifted to be 0, the variance does not change, so any statistical model we build that analyzes the variance will not be affecting by mean-centering.
2.7 Standardizing data
After we’ve mean centered the data, we can go one step further and divide by the standard deviation. This results in something often called a z-score. The process of converting variables from their original units to z-scores is called standardizing the data.
\[ Z = \frac{\left(X - \overline{X}\right)}{SD(X)} \]
What happens if you try to standardize a variable that is constant? (Hint: think about the denominator of the fraction defining the z-score.)
Why is it useful to standardize variables? One reason is that it remove the units of measurement to facilitate comparisons between variables. Suppose \(X\) represents height in inches. The numerator (\(X - \overline{X}\)) has units of inches. The standard deviation \(SD(X)\) also has units of inches. So when you divide, the units go away and the z-score is left without units, sometimes called a “dimensionless quantity”.
Suppose a female in the United States is 6 feet tall (72 inches). Suppose a female in China is 5’8 tall (68 inches). In absolute terms, the American woman is taller than the Chinese woman. But what if we’re interested in knowing which woman is taller relative to their respective population?
The mean height for an American woman is 65” with a standard deviation of 3.5” The mean height for a Chinese woman is 62” with a standard deviation of 2.5”. (These numbers aren’t perfectly correct, but they’re probably close-ish.)
Calculate the z-scores for both these women.
Which woman is taller relative to their population?
Although z-scores don’t technically have units, we can think of them as measuring how many standard deviations a value lies above or below the mean.
What is the z-score for a value that equals the mean?
What is the meaning of a negative z-score?
The z-score for the American woman was 2. This means that her height measures two standard deviations above the mean.
For real-world data, we will use technology to do this. Here are some temperature measurements from New York in 1974. (These are daily highs across a six-month period.)
airquality$Temp## [1] 67 72 74 62 56 66 65 59 61 69 74 69 66 68 58 64 66 57 68 62 59 73 61 61 57
## [26] 58 57 67 81 79 76 78 74 67 84 85 79 82 87 90 87 93 92 82 80 79 77 72 65 73
## [51] 76 77 76 76 76 75 78 73 80 77 83 84 85 81 84 83 83 88 92 92 89 82 73 81 91
## [76] 80 81 82 84 87 85 74 81 82 86 85 82 86 88 86 83 81 81 81 82 86 85 87 89 90
## [101] 90 92 86 86 82 80 79 77 79 76 78 78 77 72 75 79 81 86 88 97 94 96 94 91 92
## [126] 93 93 87 84 80 78 75 73 81 76 77 71 71 78 67 76 68 82 64 71 81 69 63 70 77
## [151] 75 76 68We calculate the mean and standard deviation:
mean(airquality$Temp)## [1] 77.88235
sd(airquality$Temp)## [1] 9.46527This is an average high of about 78 degrees Fahrenheit with a standard deviation of about 9.5 degrees Fahrenheit.
If we just subtract the mean, we get mean-centered data.
airquality$Temp - mean(airquality$Temp)## [1] -10.8823529 -5.8823529 -3.8823529 -15.8823529 -21.8823529 -11.8823529
## [7] -12.8823529 -18.8823529 -16.8823529 -8.8823529 -3.8823529 -8.8823529
## [13] -11.8823529 -9.8823529 -19.8823529 -13.8823529 -11.8823529 -20.8823529
## [19] -9.8823529 -15.8823529 -18.8823529 -4.8823529 -16.8823529 -16.8823529
## [25] -20.8823529 -19.8823529 -20.8823529 -10.8823529 3.1176471 1.1176471
## [31] -1.8823529 0.1176471 -3.8823529 -10.8823529 6.1176471 7.1176471
## [37] 1.1176471 4.1176471 9.1176471 12.1176471 9.1176471 15.1176471
## [43] 14.1176471 4.1176471 2.1176471 1.1176471 -0.8823529 -5.8823529
## [49] -12.8823529 -4.8823529 -1.8823529 -0.8823529 -1.8823529 -1.8823529
## [55] -1.8823529 -2.8823529 0.1176471 -4.8823529 2.1176471 -0.8823529
## [61] 5.1176471 6.1176471 7.1176471 3.1176471 6.1176471 5.1176471
## [67] 5.1176471 10.1176471 14.1176471 14.1176471 11.1176471 4.1176471
## [73] -4.8823529 3.1176471 13.1176471 2.1176471 3.1176471 4.1176471
## [79] 6.1176471 9.1176471 7.1176471 -3.8823529 3.1176471 4.1176471
## [85] 8.1176471 7.1176471 4.1176471 8.1176471 10.1176471 8.1176471
## [91] 5.1176471 3.1176471 3.1176471 3.1176471 4.1176471 8.1176471
## [97] 7.1176471 9.1176471 11.1176471 12.1176471 12.1176471 14.1176471
## [103] 8.1176471 8.1176471 4.1176471 2.1176471 1.1176471 -0.8823529
## [109] 1.1176471 -1.8823529 0.1176471 0.1176471 -0.8823529 -5.8823529
## [115] -2.8823529 1.1176471 3.1176471 8.1176471 10.1176471 19.1176471
## [121] 16.1176471 18.1176471 16.1176471 13.1176471 14.1176471 15.1176471
## [127] 15.1176471 9.1176471 6.1176471 2.1176471 0.1176471 -2.8823529
## [133] -4.8823529 3.1176471 -1.8823529 -0.8823529 -6.8823529 -6.8823529
## [139] 0.1176471 -10.8823529 -1.8823529 -9.8823529 4.1176471 -13.8823529
## [145] -6.8823529 3.1176471 -8.8823529 -14.8823529 -7.8823529 -0.8823529
## [151] -2.8823529 -1.8823529 -9.8823529But if we also divide by the standard deviation, we get a standardized variable (or a set of z-scores). Note the extra parentheses to make sure we get the order of operations right. We have to subtract first, but then divide that whole mean-centered quantity by the standard deviation.
## [1] -1.14971398 -0.62146702 -0.41016823 -1.67796094 -2.31185730 -1.25536337
## [7] -1.36101276 -1.99490912 -1.78361034 -0.93841519 -0.41016823 -0.93841519
## [13] -1.25536337 -1.04406459 -2.10055851 -1.46666216 -1.25536337 -2.20620791
## [19] -1.04406459 -1.67796094 -1.99490912 -0.51581762 -1.78361034 -1.78361034
## [25] -2.20620791 -2.10055851 -2.20620791 -1.14971398 0.32937752 0.11807873
## [31] -0.19886945 0.01242934 -0.41016823 -1.14971398 0.64632570 0.75197509
## [37] 0.11807873 0.43502691 0.96327387 1.28022205 0.96327387 1.59717023
## [43] 1.49152084 0.43502691 0.22372813 0.11807873 -0.09322005 -0.62146702
## [49] -1.36101276 -0.51581762 -0.19886945 -0.09322005 -0.19886945 -0.19886945
## [55] -0.19886945 -0.30451884 0.01242934 -0.51581762 0.22372813 -0.09322005
## [61] 0.54067630 0.64632570 0.75197509 0.32937752 0.64632570 0.54067630
## [67] 0.54067630 1.06892327 1.49152084 1.49152084 1.17457266 0.43502691
## [73] -0.51581762 0.32937752 1.38587145 0.22372813 0.32937752 0.43502691
## [79] 0.64632570 0.96327387 0.75197509 -0.41016823 0.32937752 0.43502691
## [85] 0.85762448 0.75197509 0.43502691 0.85762448 1.06892327 0.85762448
## [91] 0.54067630 0.32937752 0.32937752 0.32937752 0.43502691 0.85762448
## [97] 0.75197509 0.96327387 1.17457266 1.28022205 1.28022205 1.49152084
## [103] 0.85762448 0.85762448 0.43502691 0.22372813 0.11807873 -0.09322005
## [109] 0.11807873 -0.19886945 0.01242934 0.01242934 -0.09322005 -0.62146702
## [115] -0.30451884 0.11807873 0.32937752 0.85762448 1.06892327 2.01976780
## [121] 1.70281962 1.91411841 1.70281962 1.38587145 1.49152084 1.59717023
## [127] 1.59717023 0.96327387 0.64632570 0.22372813 0.01242934 -0.30451884
## [133] -0.51581762 0.32937752 -0.19886945 -0.09322005 -0.72711641 -0.72711641
## [139] 0.01242934 -1.14971398 -0.19886945 -1.04406459 0.43502691 -1.46666216
## [145] -0.72711641 0.32937752 -0.93841519 -1.57231155 -0.83276580 -0.09322005
## [151] -0.30451884 -0.19886945 -1.04406459The easier way to do this in R is to use the scale command. (Sorry, the output is a little long. Keep scrolling below.)
scale(airquality$Temp)## [,1]
## [1,] -1.14971398
## [2,] -0.62146702
## [3,] -0.41016823
## [4,] -1.67796094
## [5,] -2.31185730
## [6,] -1.25536337
## [7,] -1.36101276
## [8,] -1.99490912
## [9,] -1.78361034
## [10,] -0.93841519
## [11,] -0.41016823
## [12,] -0.93841519
## [13,] -1.25536337
## [14,] -1.04406459
## [15,] -2.10055851
## [16,] -1.46666216
## [17,] -1.25536337
## [18,] -2.20620791
## [19,] -1.04406459
## [20,] -1.67796094
## [21,] -1.99490912
## [22,] -0.51581762
## [23,] -1.78361034
## [24,] -1.78361034
## [25,] -2.20620791
## [26,] -2.10055851
## [27,] -2.20620791
## [28,] -1.14971398
## [29,] 0.32937752
## [30,] 0.11807873
## [31,] -0.19886945
## [32,] 0.01242934
## [33,] -0.41016823
## [34,] -1.14971398
## [35,] 0.64632570
## [36,] 0.75197509
## [37,] 0.11807873
## [38,] 0.43502691
## [39,] 0.96327387
## [40,] 1.28022205
## [41,] 0.96327387
## [42,] 1.59717023
## [43,] 1.49152084
## [44,] 0.43502691
## [45,] 0.22372813
## [46,] 0.11807873
## [47,] -0.09322005
## [48,] -0.62146702
## [49,] -1.36101276
## [50,] -0.51581762
## [51,] -0.19886945
## [52,] -0.09322005
## [53,] -0.19886945
## [54,] -0.19886945
## [55,] -0.19886945
## [56,] -0.30451884
## [57,] 0.01242934
## [58,] -0.51581762
## [59,] 0.22372813
## [60,] -0.09322005
## [61,] 0.54067630
## [62,] 0.64632570
## [63,] 0.75197509
## [64,] 0.32937752
## [65,] 0.64632570
## [66,] 0.54067630
## [67,] 0.54067630
## [68,] 1.06892327
## [69,] 1.49152084
## [70,] 1.49152084
## [71,] 1.17457266
## [72,] 0.43502691
## [73,] -0.51581762
## [74,] 0.32937752
## [75,] 1.38587145
## [76,] 0.22372813
## [77,] 0.32937752
## [78,] 0.43502691
## [79,] 0.64632570
## [80,] 0.96327387
## [81,] 0.75197509
## [82,] -0.41016823
## [83,] 0.32937752
## [84,] 0.43502691
## [85,] 0.85762448
## [86,] 0.75197509
## [87,] 0.43502691
## [88,] 0.85762448
## [89,] 1.06892327
## [90,] 0.85762448
## [91,] 0.54067630
## [92,] 0.32937752
## [93,] 0.32937752
## [94,] 0.32937752
## [95,] 0.43502691
## [96,] 0.85762448
## [97,] 0.75197509
## [98,] 0.96327387
## [99,] 1.17457266
## [100,] 1.28022205
## [101,] 1.28022205
## [102,] 1.49152084
## [103,] 0.85762448
## [104,] 0.85762448
## [105,] 0.43502691
## [106,] 0.22372813
## [107,] 0.11807873
## [108,] -0.09322005
## [109,] 0.11807873
## [110,] -0.19886945
## [111,] 0.01242934
## [112,] 0.01242934
## [113,] -0.09322005
## [114,] -0.62146702
## [115,] -0.30451884
## [116,] 0.11807873
## [117,] 0.32937752
## [118,] 0.85762448
## [119,] 1.06892327
## [120,] 2.01976780
## [121,] 1.70281962
## [122,] 1.91411841
## [123,] 1.70281962
## [124,] 1.38587145
## [125,] 1.49152084
## [126,] 1.59717023
## [127,] 1.59717023
## [128,] 0.96327387
## [129,] 0.64632570
## [130,] 0.22372813
## [131,] 0.01242934
## [132,] -0.30451884
## [133,] -0.51581762
## [134,] 0.32937752
## [135,] -0.19886945
## [136,] -0.09322005
## [137,] -0.72711641
## [138,] -0.72711641
## [139,] 0.01242934
## [140,] -1.14971398
## [141,] -0.19886945
## [142,] -1.04406459
## [143,] 0.43502691
## [144,] -1.46666216
## [145,] -0.72711641
## [146,] 0.32937752
## [147,] -0.93841519
## [148,] -1.57231155
## [149,] -0.83276580
## [150,] -0.09322005
## [151,] -0.30451884
## [152,] -0.19886945
## [153,] -1.04406459
## attr(,"scaled:center")
## [1] 77.88235
## attr(,"scaled:scale")
## [1] 9.46527Although the outputs are formatted a little differently, you can go back and check that these sets of numbers match each other.
What is the mean of a standardized variable? How do you know this?
Let’s calculate the variance of a standardized variable. To do so, I’ll note that the mean \(\overline{X}\) is just a number. Also, the standard deviation \(SD(X)\) is just a number. To make the calculation easier to understand, let’s just substitute letters that are easier to work with:
\(M = \overline{X}\)
\(S = SD(X)\)
Remember, \(M\) and \(S\) are constants.
Now we need to calculate \(Var(Z)\). I’ll do the first couple of steps. Then you take over and, using the variance rules from earlier in the chapter, simplify the expression until you get to a numerical answer. Be sure to justify each step by citing the rule you invoked to get there.
\[\begin{align} Var(Z) &= Var\left(\frac{\left(X - \overline{X}\right)}{SD(X)}\right) \\ &= Var\left(\frac{\left(X - M\right)}{S}\right) \\ &= Var\left(\frac{1}{S}\left(X - M\right)\right) \\ &= \quad ??? \end{align}\]
You may feel a little uncomfortable applying Rule 3 because you might worry if \(X\) and \(M\) are independent. Since \(M\) is the mean of \(X\), it seems like that is very dependent on \(X\). This is where some of the intuition about independence breaks down and we have to rely on mathematical rules that we haven’t really gotten into. All constants are independent of any other variable.
You should get the answer 1. A standardized variable always has variance 1. This will be an important fact in future chapters.