4 Simple regression
Preliminaries
We need to load the packages we will use for this chapter. The tidyverse package has all sorts of utilities for working with tibbles (data frames). The broom package will be used to calculate and store the residuals of the model. This will also be our first introduction to the lavaan package that will be used throughout the rest of the book.
## This is lavaan 0.6-11
## lavaan is FREE software! Please report any bugs.4.1 Some friendly advice
Even if you have seen regression before reading this book, be sure to read and study the this chapter and the next chapter thoroughly. If nothing else, you need to be comfortable with the notation and terminology established here. But we will also take special care to motivate and justify all the calculations that are taken for granted in some treatments of regression. This framework will be important as we move into mediation and path analysis in the following chapters. If you are comfortable with the content of this chapter, there won’t be much “new” to say about multiple regression, mediation, and path analysis more generally.
4.2 Prediction
One of the most important tasks in statistics is prediction. Given some data, can we predict the value of something important about a population of interest?
Suppose you have gathered some data on anxiety among Utah high school students. There are various instruments available for measuring anxiety, so say you have administered the Beck Anxiety Inventory. This instrument assigns a score from 0 to 63, with lower numbers indicating less anxiety and higher numbers indicating more.
You take care to make sure your sample is as close to a simple random sample as possible so that it’s representative of the population (all high school students in the state of Utah). From your sample data, you can calculate summary statistics. For example, you might find that the mean anxiety score for Utah high school students is 7.1 with a standard deviation of 3.9.
A random Utah high school student walks through the door. You don’t know anything about them. Can you say anything about their anxiety? What is your best guess as to what their score might be on the Beck Anxiety Inventory?
We can do a lot better if we have another variable we can measure. For example, let’s suppose our data records not only anxiety, but also the minutes of smart phone usage per day.
In theory, why would having information about smart phone usage potentially help us make better predictions of anxiety?
Do you suspect that the association between anxiety and smart phone usage is positive or negative? (You can Google this question to check if there is any empirical evidence out there for your guess.)
Now imagine that another random Utah high school student walks through the door. This time, I tell you that their smart phone usage is average (sitting at the mean). What is your best prediction for their anxiety score? (Give an exact value.)
What if I told you that the student who walked through the door had higher than average smart phone usage? What would be your prediction of their anxiety score? (You can’t give an exact value here, but give a qualitatively sensible answer.)
What if I told you that the student who walked through the door had lower than average smart phone usage? What would be your prediction of their anxiety score? (Again, just give a qualitatively sensible answer.)
4.3 Regression terminology
When we have one variable we suspect may help us predict another variable, one way to study it is using a simple regression model.
This is related to, but somewhat different from, covariance. Covariance is symmetric, so it expresses the idea that two variables are mutually related. But there is no “directionality” to that relationship. By way of contrast, a simple regression model asserts that one of the variables is a “predictor” and the other is “response”. In other words, we start with the values or properties of the predictor variable and try to deduce what we can about the values or properties of the response variable.
Keep in mind that “directionality” is not the same as “causality”. While it’s possible that one variable causes another, there needs to be a data collection process (often a carefully controlled experiment) and a clear scientific rationale that justifies a causal relationship between variables before we can start thinking about inferring causality. For purposes of much of this book, directionality just means that we wish to establish a predictive relationship wherein we start with the properties of one variable and try to predict the properties of another variable. There is often a “sensible” order in which to do this based on the research questions asked or the hypotheses posed.
There are many different terminological conventions in statistics, so be aware that “predictor” variables are also called—often depending on the discipline and the context—features, covariates, controls, regressors, inputs, explanatory variables, or independent variables. In fact, in the context of structural equation modeling, we will use the term “exogenous” to refer to variables that play this role. (That term has a much more precise definition that we’ll discuss in future chapters.) And “response” variables might be called outcomes, outputs, targets, criteria, predicted variables, explained variables, or dependent variables, among others. In this book, we will often use the term “endogenous” (again, in a very specific way yet to be explained). If there is a data collection process and a clear scientific rationale that justifies a causal relationship between variables, then we might be able to refer to variables as either “cause” or “effect”.
Keep in mind that it’s the scientific question we want to ask that determines the predictor/response relationship. A different researcher with a different hypothesis might use the same two variables but with the roles reversed.
In the anxiety/smart-phone example above, which variable is predictor and which is response, at least according to the way we stated the scenario?
4.4 The simple regression model
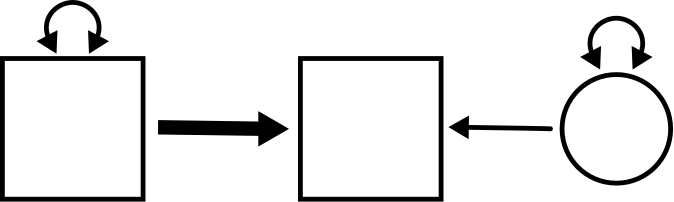
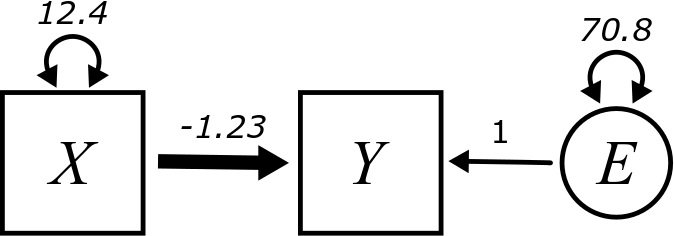
Here is the figure from the top of the chapter, only now we have decorated it with some letters (and a number):
The goal of this section is to explain all these.
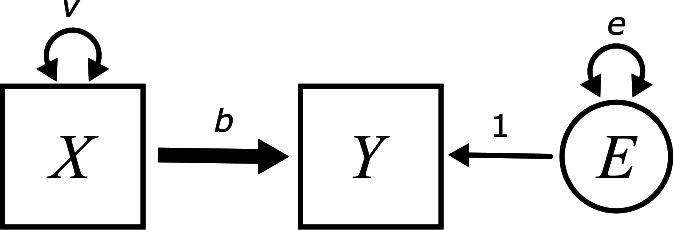
The variable names are \(X\) and \(Y\). \(X\) is the exogenous variable and \(Y\) is the endogenous variable. For example, \(X\) might be smart phone usage and \(Y\) might be the anxiety score from the example above. In this section, we’re going to do some concrete calculations using the example from the last chapter about wind speed and temperature from the airquality data set. In the last chapter, we simply calculated the (symmetric) correlation between wind speed and temperature. Here, we will consider wind speed as exogenous and temperature as endogenous. In other words, our goal is to use the wind speed as a predictor of temperature.
The letter \(v\) requires no further explanation. This is the variance of the variable \(X\), so we already know about it.
The parameter \(b\) is supposed to measure something about the predictive relationship between \(X\) and \(Y\). It is attached to an arrow that is drawn a little thicker than the other arrows in the diagram. More to say about that in a moment.
The really weird, new part is the circle on the right. This will be the “error” term.
What is “error” and why is it here? To illustrate, let’s plot wind speed against temperature. Before plotting and analyzing these variables, we are going to mean-center them and put them in a tibble.
X <- airquality$Wind - mean(airquality$Wind)
Y <- airquality$Temp - mean(airquality$Temp)
airquality_mc <- tibble(X, Y)
airquality_mc## # A tibble: 153 × 2
## X Y
## <dbl> <dbl>
## 1 -2.56 -10.9
## 2 -1.96 -5.88
## 3 2.64 -3.88
## 4 1.54 -15.9
## 5 4.34 -21.9
## 6 4.94 -11.9
## 7 -1.36 -12.9
## 8 3.84 -18.9
## 9 10.1 -16.9
## 10 -1.36 -8.88
## # … with 143 more rows
ggplot(airquality_mc, aes(y = Y, x = X)) +
geom_point()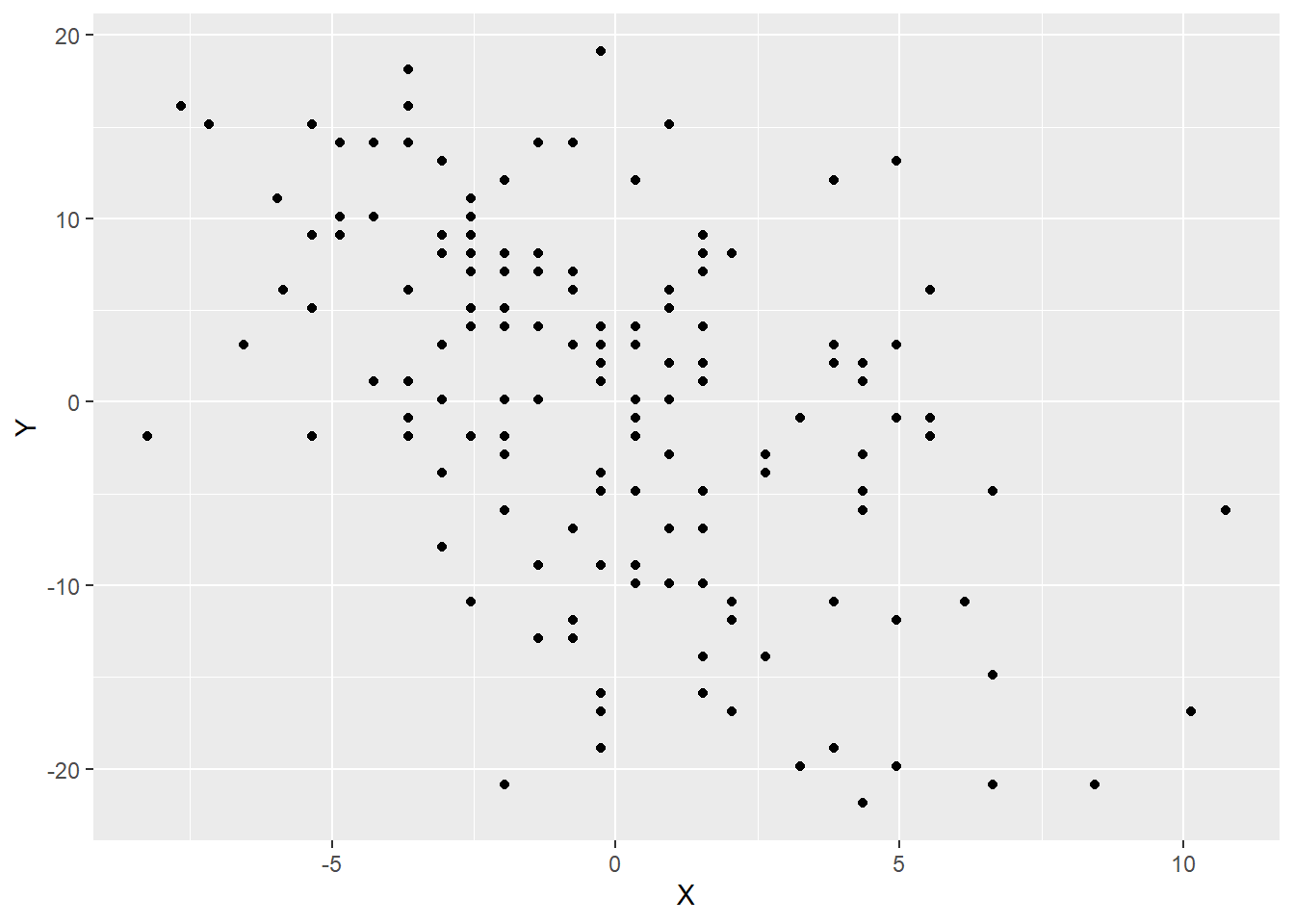
Note that the exogenous variable (wind speed) is on the x-axis and the endogenous variable (temperature) is on the y-axis.
We can see a negative and reasonably linear association between these variables, so let’s add a line of best fit to the data.
ggplot(airquality_mc, aes(y = Y, x = X)) +
geom_point() +
geom_smooth(method = lm, se = FALSE)## `geom_smooth()` using formula 'y ~ x'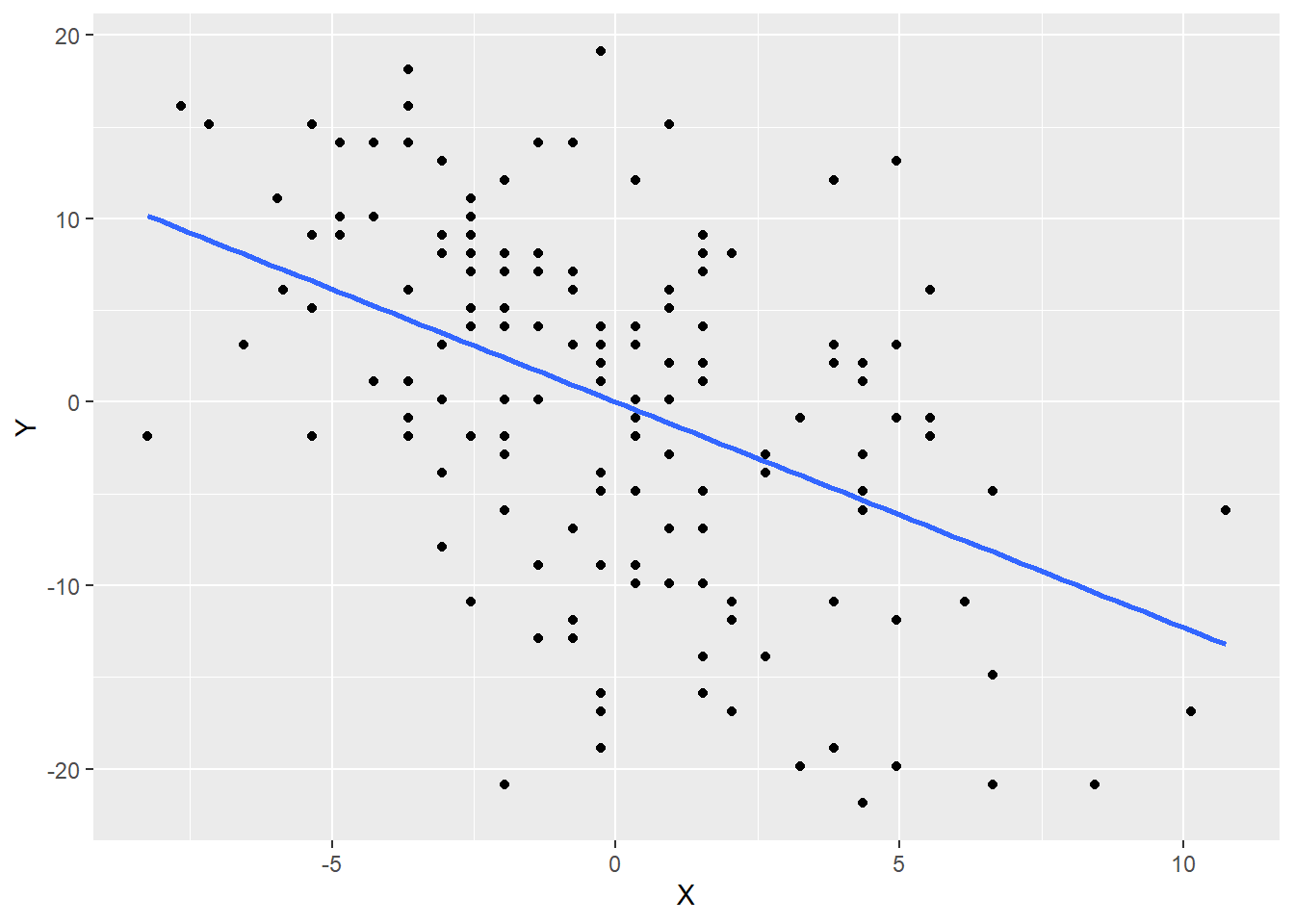
The line passes right through the origin \((0, 0)\). Why?
The slope of this line is \(-1.23\). We’ll see how to calculate this slope in a bit. But what does this slope mean?
Look at the help file for the airquality data set. (Either use the Help tab in RStudio or type ?airquality at the Console.)
What are the units of measurement of \(X\)? What are the units of measurement of \(Y\)? Since slope is “rise over run”, what are the units of the slope?
So, the idea is that for every additional mile per hour of wind speed, we predict that the temperature goes down by 1.23 degrees Fahrenheit.
Why is the following sentence incorrect?
For every additional mile per hour of wind speed, the temperature goes down by 1.23 degrees Fahrenheit.
The point is that the line is a model that makes predictions. As long as \(X\) and \(Y\) are both mean-centered, the equation of this line is
\[ \hat{Y} = bX \]
There is a new piece of notation here: \(\hat{Y}\). This symbol represents the predicted value of \(Y\) according to the model. We will not get the actual value of \(Y\) from this piece of the model because the actual values of \(Y\) differ from the model because real-world data doesn’t lie on a perfect straight line. More on that in a moment.
According to the information above, we can estimate that the value of \(b\) is \(-1.23\):
\[ \hat{Y} = -1.23X \]
This is a proportional effect. Again, as long as \(X\) and \(Y\) are both mean-centered, knowing the value of \(X\) allows us to predict the value of \(Y\) by multiplying by \(b\).
But those predictions will almost always be wrong. On any given day, given an increase of 1 mile per hour wind in wind speed, it will very rarely happen that the temperature will drop by exactly 1.23 degrees. That’s just a sort of “average” over time. On average, there’s a slight temperature change associated with 1 mph change in wind speed, and the number -1.23 is the best estimate of that average change across our whole data set. We need to be especially clear that an increase in wind speed does not necessary cause a drop in temperature. I mean, that might be partially true, but we can’t prove it from our observational data. There are all sorts of other reasons to explain both an increase in wind speed and a drop in temperature (like a cold front moving in).
Since our predictions are average effects and not specific guarantees, every prediction we make will be wrong by some amount. (We could get extremely lucky, but even then, it’s difficult to imagine a situation in which our prediction is precisely correct to, say, 10 decimal places or something like that.) Therefore, there is error in our prediction. The new equation—accounting for error—is
\[ Y = bX + E \] or \[ Y = -1.23X + E \]
Now we use \(Y\) instead of \(\hat{Y}\). Once we include the error, we can recover the exact value of \(Y\), so this is no longer just a prediction from the straight-line model. Remember this:
If you write down a regression equation for an endogenous variable that includes all incoming arrows, including the error term, use \(Y\).
If you write down a regression equation for an endogenous variable that includes all incoming arrows, excluding the error term, use \(\hat{Y}\).
Error is a funny word because it has a negative connotation. It sounds like we made a mistake. Well, the model does make mistakes. Every model prediction is technically wrong. But this is not the kind of mistake that results from doing our arithmetic wrong or anything like that. It’s simply the “natural” error that results from the messiness of the real world and the impossibility of predicting anything with certainty. For this reason, we will often prefer the term “residual”. It’s what is “left over” after we have made a prediction. It’s the extra change in temperature, for example, that is not accounted for by the model with wind speed alone.
The residuals are evident in the plot above. If there were no residuals, every data point would lie on a perfect straight line. But the data points are all either a little above or below the line. Those vertical distances between the data and the line are the residuals or errors. Here is an example of two residuals plotted below in red.
ggplot(airquality_mc, aes(y = Y, x = X)) +
geom_point() +
geom_smooth(method = lm, se = FALSE) +
annotate("segment",
x = -2.56, y = 3.15,
xend = -2.56, yend = 3.15 - 14.03,
color = "red", size = 1.5) +
annotate("segment",
x = 4.94, y = -6.08,
xend = 4.94, yend = -6.08 + 9.20,
color = "red", size = 1.5)## `geom_smooth()` using formula 'y ~ x'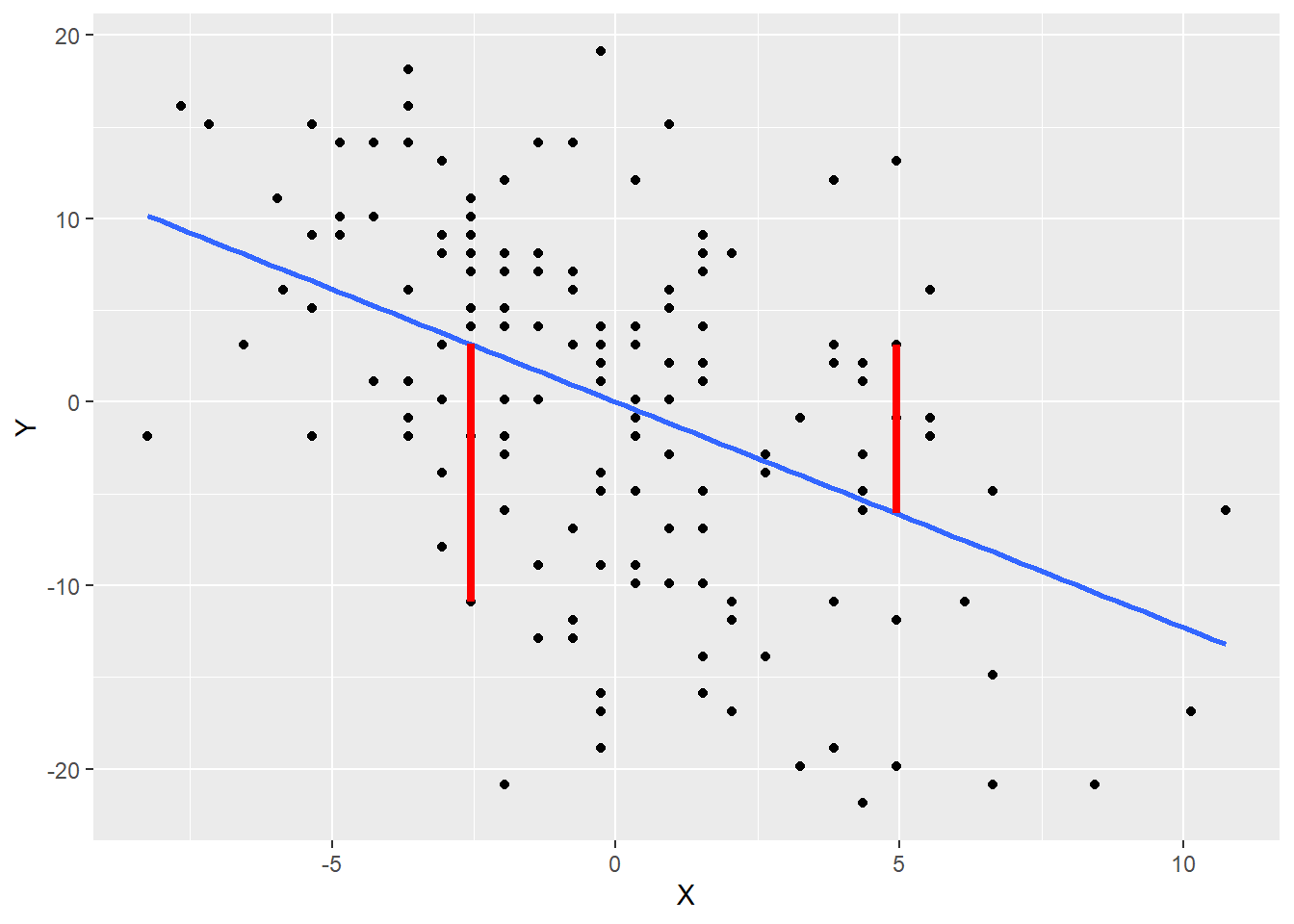
Points below the line have negative residuals and points above the line have positive residuals.
The residuals do not appear as observed or measured variables in our data. They are a consequence of a variety of unmeasured factors that determine temperature aside from wind speed. An unmeasured variable that appears in a model is called a latent variable. We will discuss latent variables in far greater detail in Chapter 8. For now, just know that latent variables are indicated by circles in the diagram. That’s why there is a circle with the letter \(E\) inside.
The equation
\[ Y = bX + E \] can also be written as \[ Y = bX + 1 \cdot E \]
How is that “1” represented in the diagram?
The letters \(v\), \(b\), and \(e\) are called free parameters because they are free to vary depending on the data. The “1” is called a fixed parameter. It is attached to an arrow, so it’s technically a parameter of the model, but it is not a parameter that we need to calculate. It is “fixed” at the value 1 because the error term in the model is represented by \(+E\) with a fixed coefficient of 1. In general, throughout the book, if the word “parameter” is used without qualification, you can assume we are talking only about the free parameters, the ones we need to calculate.
Arrows that represent the coefficients of regression relationships will be drawn a little thicker than the other arrows in the diagram. This convention is, to our knowledge, unique to this book. It is not absolutely necessary, but it will be helpful later when there are more arrows floating about to distinguish between the regression relationship and other kinds of relationships (like error terms or covariances, for example).
The only thing in the diagram that hasn’t been explained yet is \(e\).
Where does \(e\) appear in the diagram? Given where it appears, what does it represent mathematically?
We know that curved arrows represent variance. But what does it mean to measure the variance of a variable we can’t observe?
What would the scatterplot look like if the error variance were very small. What about if the error variance were large?
There is variability in the size of the residuals. Some are small (points that are close to the line) and some are large (points that are far from the line). This spread of residuals can be estimated from data, just like any other variance calculation.14 It turns out to be about 70.8. We’ll see how to calculate that below.
Let’s put everything together into a diagram.
First, we need the variance of \(X\) (wind speed). Calculate it in R. You should get 12.4.
Does it matter if you calculate the variance of the variable Wind from the original airquality data, or the variance of the \(X\) variable from airqualilty_mc? Why or why not?
While it’s helpful to see \(X\) and \(Y\) as generic prototypes for any simple regression model, in most applied problems from now on we’ll refer to variables using contextually meaningful names. The final diagram looks like this:
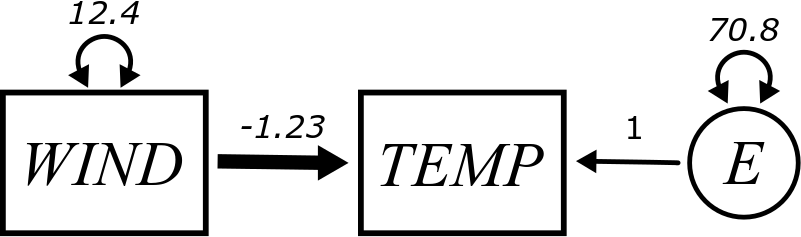
Is the error variable \(E\) exogenous or endogenous?
One final note about this diagram: you may have noticed that the \(Y\) variable (or \(\textit{TEMP}\)) does not have a variance term attached. There is no double-headed arrow on that box. Why not? The point here is that we are trying to understand the variance of \(Y\) using other elements of the model. In other words, \(Y\) has a variance, but that variance is partially predicted by \(X\). And the rest of the variance not predicted by \(X\) is swept up in the error term \(E\). So all the variance is \(Y\) is accounted for through the contribution of \(X\) and \(E\) combined.
4.5 Simple regression assumptions
All the calculations we need to do, and our ability to interpret the results, depend on certain assumptions being met.
If you look up regression assumptions, you might find a huge list of requirements. Some of these requirements relate to calculating statistics like P-values for regression parameters. For now, we are content simply to know that it makes sense to interpret the parameters in the model above.
For that, we really only need five assumptions:
- The data should come from a “good” sample.
- The values of the exogenous variable should be measured without error.
- The relationship between \(Y\) and \(X\) should be approximately linear.
- The residuals should be independent of the \(X\) values.
- There should be no influential outliers.
Let’s address these one at a time:
- What do we mean by a “good” sample? While a simple random sample is the gold standard, it’s usually not possible to obtain one in the real world. So we make our sampling process as random as possible and ensure that the resulting sample is as representative of the population we’re trying to study as possible.
- We should always strive to measure things precisely. When measuring physical phenomena with precise scientific instruments, we can usually minimize so-called “measurement error”. But some measurements are a lot messier. You might ask a person a series of survey questions today and then ask them the same questions tomorrow and get somewhat different answers. Or you might have to record data that consists of “educated guess” estimates about things that are difficult to pin down precisely. Whenever you have an exogenous variable that is unreliable, that can introduce bias into your model. (Curiously, measurement error in the endogenous variable doesn’t matter quite as much. It may introduce more variability in your estimates, but it will not bias the values of the parameters of the regression model.)
- You can check linearity with a scatterplot. Just make sure the pattern of dots doesn’t have strong curvature to it.
- There should be no patterns in the residuals at all. They should be randomly scattered around the best-fit line and the average size of the residuals should not change radically from one side of the graph to the other.15 You can check this by plotting the residuals, but that can’t be done until after the model is fit. (The residuals don’t exist until we have a value of \(\hat{Y}\) with which to compare \(Y\).)
- Check the scatterplot for outliers. If there are serious ones, assess them to make sure they are not data entry mistakes. If they correspond to valid data, you cannot just throw them away.16 Often, the solution is to run the analysis both including and (temporarily) excluding the outliers to make sure their presence doesn’t radically alter the parameter estimates.
4.6 Calculating regression parameters
Now we’ll show one way to calculate the parameters (the numbers) in the above diagram. This isn’t the only way to do it. In fact, this is not the approach that is used in most intro stats classes. But this approach will be helpful to illustrate the way we will do these calculations in future chapters.
Let’s go back to the diagram without the numbers:
The letter \(v\) is easy because it’s just the variance of \(X\):
\[ Var(X) = v \]
We can estimate it directly from the data. (You already did it in R above for wind speed.) Through completing the activities below, we will also calculate \(b\) and \(e\).
To get the other parameters, we have to set up a few equations. The first observation we need to make is that, as important as the arrows are in a diagram, it’s just as important where the arrows are not.
Are there any arrows directly connecting \(X\) and \(E\)? What might that imply about the relationship between \(X\) and \(E\)? Which regression assumption is related to this question?
So what would that imply about the value of \(Cov(E, X)\)?
We have to be a little careful with the line of reasoning above. Even if there are no direct paths from \(X\) to \(E\), are there any indirect paths from \(X\) to \(E\)? Such an indirect path might be the source of some kind of association between \(X\) and \(E\).
The only possible path goes through \(Y\) and looks like \[ X \boldsymbol{\rightarrow} Y \leftarrow E \] For reasons that we won’t explain here (but will be explained in Chapter 6), this type of path does not imply any kind of association between \(X\) and \(E\). Therefore, the model does imply that \(X\) and \(E\) are independent, and, therefore, \(Cov(E, X) = 0\).
Next, because \(Y\) is the combination of \(X\) and \(E\), we’ve already seen that we can write
\[ Y = bX + E \]
Therefore, we can calculate \(Var(Y)\) according to this formula using the established rules. (A convenient list of all of them in one place is located in Appendix A.)
Keep simplifying the following as much as possible:
\[\begin{align} Var(Y) &= Var(bX + E) \\ &= \quad ??? \end{align}\]
You should end up with
\[ b^{2}v + e \]
Don’t forget that \(Var(X) = v\) and \(Var(E) = e\) in the diagram!
We also need to use information about the covariance between \(Y\) and \(X\). Keep simplifying the calculation below:
\[\begin{align} Cov(Y, X) &= Cov(bX + E, X) \\ &= \quad ??? \end{align}\]
You should end up with
\[ bv \]
Use R to calculate \(Var(Y)\) and \(Cov(Y, X)\) for the airquality data. (You’ve already computed \(Var(X)\). It was 12.4.)
You should get 89.6 and -15.3, respectively.
Now we can set up all the equations we need to solve for the various letters we want. Here are the three equations we have established:
\[\begin{align} 12.4 &= v \\ 89.6 &= b^2v + e \\ -15.3 &= bv \end{align}\]
Time to do a little algebra. You know \(v\). Using that value, solve for \(b\) first (using the last equation). Then, using both values of \(b\) and \(v\), solve for \(e\) in the second equation.
Check that the values you got are the same as the ones from the earlier diagram (with the possibility of a little rounding error).
Now let’s go through that again, but this time, in full generality:
\[\begin{align} Var(X) &= v \\ Var(Y) &= b^2v + e \\ Cov(Y, X) &= bv \end{align}\]
Therefore,
\[ v = Var(X) \]
\[ b = \frac{Cov(Y, X)}{Var(X)} \]
\[ e = Var(Y) - \left( \frac{Cov(Y, X)}{Var(X)} \right)^2 Var(X) \]
4.7 The model-implied matrix
It will be convenient in future chapters to collect up all these numbers we need in an array of terms called a sample covariance matrix. (Sometimes this is called a variance-covariance matrix.) The idea is to take the covariance of all possible pairs of observed variables and arrange them as follows:
\[ \begin{bmatrix} Cov(X, X) & Cov(X, Y) \\ Cov(Y, X) & Cov(Y, Y) \\ \end{bmatrix} \]
There are some immediate simplifications to make.
- Since \(Cov(X, Y) = Cov(Y, X)\), there is no point in writing it twice. We will just use a dot (\(\bullet\)) to replace \(Cov(X, Y)\).
- We can replace the upper-left and lower-right entries (the entries on the so-called “diagonal” of the matrix) with variances.
This is our final sample covariance matrix:
\[ \begin{bmatrix} Var(X) & \bullet \\ Cov(Y, X) & Var(Y) \\ \end{bmatrix} \]
Alternatively, we could also write this:
\[ \begin{bmatrix} Var(X) & Cov(X, Y) \\ \bullet & Var(Y) \\ \end{bmatrix} \]
The former is called the lower-triangular form, and the latter is the upper-triangular form. Both contain the same information, so it really doesn’t matter which one we use.
With the data we have, we can calculate numbers for all these quantities.
There is another important matrix called the model-implied matrix. Given the model, what does the covariance matrix look like? From the calculations above, we know that the model-implied matrix is
\[ \begin{bmatrix} v & \bullet \\ bv & b^{2}v + e \\ \end{bmatrix} \]
The letters \(b\), \(v\), and \(e\) are unknowns. Okay, \(v\) is not very unknown. It’s an unknown in the sense of being a parameter in the model, but you don’t have to work very hard to find it. The point is that model parameters are estimated by equating the covariance matrix (calculated from the data) with model-implied matrix and trying to solve for all the unknown parameters.
There is no new math to do in this section. The matrices are just convenient ways to organize the work we’ve already done. All parameter estimation in structural equation modeling is essentially setting these two matrices (the sample covariance matrix and the model-implied matrix) equal to each other and solving:
\[ \begin{bmatrix} Var(X) & \bullet \\ Cov(Y, X) & Var(Y) \\ \end{bmatrix} = \begin{bmatrix} v & \bullet \\ bv & b^{2}v + e \\ \end{bmatrix} \]
Don’t forget that the matrix on the left—the sample covariance matrix—consists of numbers that we calculate from data. The matrix on the right—the model-implied matrix—contains letters, which are the unknown parameters we’re trying to find.
4.8 Coefficients in terms of correlation
The formulas we derived are fine as far as they go. They allow you to take quantities calculated from data (variances and covariances of observed variables) and translate that into estimates of model parameters.
The formula for the slope parameter \(b\) is pretty simple and has some intuitive content. It’s the covariance between \(Y\) and \(X\), but dividing by the variance of \(X\) to make sure it has the right units.
\[ b = \frac{Cov(Y, X)}{Var(X)} \]
Another way to look at this formula is to rearrange things a bit as follows:
The formula for \(b\) above is equivalent to
\[ b = \frac{Cov(Y, X) \sqrt{Var (Y)}}{Var(X)\sqrt{Var(Y)}} \]
Why?
Now write it like this:
\[ b = \frac{Cov(Y, X) \sqrt{Var (Y)}}{\sqrt{Var(X)}\sqrt{Var(X)}\sqrt{Var(Y)}} \]
What happened here?
Finally, write it like this:
\[ b = \left(\frac{Cov(Y, X)}{\sqrt{Var(X)} \sqrt{Var(Y)}}\right) \left(\frac{\sqrt{Var(Y)}}{\sqrt{Var(X)}}\right) \]
Explain why this simplifies to
\[ b = Corr(Y, X)\left(\frac{SD(Y)}{SD(X)}\right) \]
This is often the formula taught in intro stats classes. In more concise notation:
\[ b = r_{YX}\left(\frac{s_{Y}}{s_{X}}\right) \]
The intuition here is that \(b\) is basically just the correlation between \(Y\) and \(X\), but it has to account for the scales and units of \(Y\) and \(X\).
Why does the standard deviation of \(Y\) have to be in the numerator and the standard deviation of \(X\) have to be in the denominator? Think about the units \(b\) must have.
The formula for the error variance \(e\) is a little more gross. With similar trickery, though, we can simplify that formula quite a bit.
Here is the starting point:
\[ e = Var(Y) - \left( \frac{Cov(Y, X)}{Var(X)} \right)^2 Var(X) \]
Explain why the right-hand side can be rewritten as
\[ Var(Y) - \frac{Cov(Y, X)^{2}}{Var(X)} \]
Explain why the next step is valid:
\[ Var(Y) - \frac{Cov(Y, X)^{2} Var(Y)}{Var(X) Var(Y)} \]
What about this next one?
\[ Var(Y) \left( 1 - \frac{Cov(Y, X)^{2}}{Var(X) Var(Y)} \right) \]
Why would we do such a thing? In other words, does the new fraction on the right look familiar in any way?
We hope you recognize that the fraction on the right is just the correlation coefficient squared. The whole equation can now be written as
\[ e = Var(Y) \left( 1 - r_{YX}^2 \right) \]
There is a nice consequence of this last equation. The term in parentheses \(\left( 1 - r_{YX}^2 \right)\) is a number between 0 and 1, right? Since we are multiplying this by the variance of \(Y\), we can think of the term in parentheses as a proportion. All the variance of \(Y\) is explained in our model in one of two ways. The thick arrow coming in from the left uses \(X\) to predict some of the variance of \(Y\). All the rest of the variance of \(Y\) is left over in the error term \(e\). Therefore, \(\left( 1 - r_{YX}^2 \right)\) is the proportion of the variance of \(Y\) left over as error.
And if that is true, it must also be the case that \(r_{YX}^2\) is the proportion of the variance of \(Y\) explained by \(X\). Calculating one minus a proportion gives the complementary proportion. For example, if \(\left( 1 - r_{YX}^2 \right) = 0.3\), then 30% of the variance of \(Y\) is left over as error. But that implies that 70% of the variance of \(Y\) is explained by \(X\). \(1 - 0.3 = 0.7\).
Most authors will write \(R^{2}\) instead of \(r^{2}\) for some reason. Rearranging the equation above, replacing \(r_{YX}^{2}\) with \(R^{2}\), and writing \(e\) as \(Var(E)\) looks like
\[ R^{2} = 1 - \frac{Var(E)}{Var(Y)} \]
In other words, we can think of the error variance as a proportion of the total variance of \(Y\), and then \(R^2\) is the complementary proportion. Therefore, \(R^{2}\) is the proportion of the variance accounted for by the model.
4.9 Regression with standardized variables
Recall that if we convert our variables to z-scores, variances are all 1 and covariances become correlation coefficients. In other words, the covariance matrix becomes a correlation matrix and looks like this:
\[ \begin{bmatrix} 1 & \bullet \\ r_{YX} & 1 \\ \end{bmatrix} \]
The model-implied matrix does not change. Solving for the parameters as before is the same, then, except we can now replace \(Var(X)\) and \(Var(Y)\) with 1, and \(Cov(Y, X)\) with \(r_{YX}\).
\[ \begin{bmatrix} 1 & \bullet \\ r_{YX} & 1 \\ \end{bmatrix} = \begin{bmatrix} v & \bullet \\ bv & b^{2}v + e \\ \end{bmatrix} \]
\[\begin{align} 1 &= v \\ r_{YX} &= bv \\ 1 &= b^2v + e \end{align}\]
Therefore,
\[ v = 1 \]
\[ b = r_{YX} \]
\[ e = 1 - r_{YX}^{2} \]
When the variables are standardized, the slope of the regression is just the correlation! And the error variance is just a proportion between 0 and 1 which is complementary to \(r_{YX}^{2}\) (aka, \(R^{2}\), or the variance explained by the model). Those two variances, \(e\) and \(R^{2}\) now add up to 1.
We’ll use the scale command to create standardized variables for temperature and wind speed and put them in a new tibble.
X_std <- scale(airquality$Wind)
Y_std <- scale(airquality$Temp)
airquality_std <- tibble(X_std, Y_std)
airquality_std## # A tibble: 153 × 2
## X_std[,1] Y_std[,1]
## <dbl> <dbl>
## 1 -0.726 -1.15
## 2 -0.556 -0.621
## 3 0.750 -0.410
## 4 0.438 -1.68
## 5 1.23 -2.31
## 6 1.40 -1.26
## 7 -0.385 -1.36
## 8 1.09 -1.99
## 9 2.88 -1.78
## 10 -0.385 -0.938
## # … with 143 more rowsModify the ggplot code from earlier in the chapter to create a scatterplot of the new standardized variables along with a best-fit line. What is the slope of this line? (Hint: calculate the correlation coefficient between the two standardized variables.)
4.10 Simple regression in R
4.10.1 Using lm
The straightforward way to run regression in R is to use the lm command. This stands for “linear model”. It uses a special symbol, the tilde ~, to express the relationship between the endogenous variable and the exogenous variable. The endogenous (response) variable always goes on the left, before the tilde. The exogenous (predictor) variable goes on the right, after the tilde. Finally, there is a data argument to tell lm where to find the variables to model.
YX_lm <- lm(Y ~ X, data = airquality_mc)
YX_lm##
## Call:
## lm(formula = Y ~ X, data = airquality_mc)
##
## Coefficients:
## (Intercept) X
## 1.117e-14 -1.230e+00Which of the two numbers above is the slope \(b\)?
We haven’t talked about the intercept yet, but according to this output, what is it? (Hint: it’s not literally \(1.117 \times 10^{-14}\). What does that number really mean?)
Run the lm command, but this time using the standardized variables from the airquality_std tibble. The value of the slope should not surprise you. Explain why it is what it is.
Don’t forget: these parameters make no sense to interpret unless the regression assumptions are met. We looked at a scatterplot already and determined that is was approximately linear. But we haven’t checked the residuals.
The residuals can be obtained most easily from the model by using the augment command from the broom package in the following way:
YX_aug <- augment(YX_lm)
YX_aug## # A tibble: 153 × 8
## Y X .fitted .resid .hat .sigma .cooksd .std.resid
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 -10.9 -2.56 3.15 -14.0 0.0100 8.39 0.0141 -1.67
## 2 -5.88 -1.96 2.41 -8.29 0.00857 8.44 0.00420 -0.986
## 3 -3.88 2.64 -3.25 -0.631 0.0102 8.47 0.0000292 -0.0751
## 4 -15.9 1.54 -1.90 -14.0 0.00780 8.39 0.0109 -1.66
## 5 -21.9 4.34 -5.34 -16.5 0.0165 8.36 0.0328 -1.98
## 6 -11.9 4.94 -6.08 -5.80 0.0195 8.46 0.00478 -0.694
## 7 -12.9 -1.36 1.67 -14.6 0.00751 8.39 0.0113 -1.73
## 8 -18.9 3.84 -4.73 -14.2 0.0144 8.39 0.0208 -1.69
## 9 -16.9 10.1 -12.5 -4.40 0.0611 8.46 0.00942 -0.538
## 10 -8.88 -1.36 1.67 -10.6 0.00751 8.43 0.00596 -1.25
## # … with 143 more rowsThere are many columns here and we’re not going to discuss most of them, but the residuals of the model are stored in the column called .resid. There are also standardized residuals stored in column std.resid. Both will look exactly the same in a plot except for the scale of the axes, so it doesn’t much matter which we use.
The residuals are now stored in a new tibble called YX_aug, so be sure to use that in the following ggplot command and not the original data. We’ll put the residuals on the y-axis. Since we’re interested in checking that the residuals are independent of the \(X\) variable, we will put that, unsurprisingly, on the x-axis. A reference line at \(y = 0\) helps us see where the residuals are centered.
ggplot(YX_aug, aes(y = .resid, x = X)) +
geom_point() +
geom_hline(yintercept = 0, color = "blue")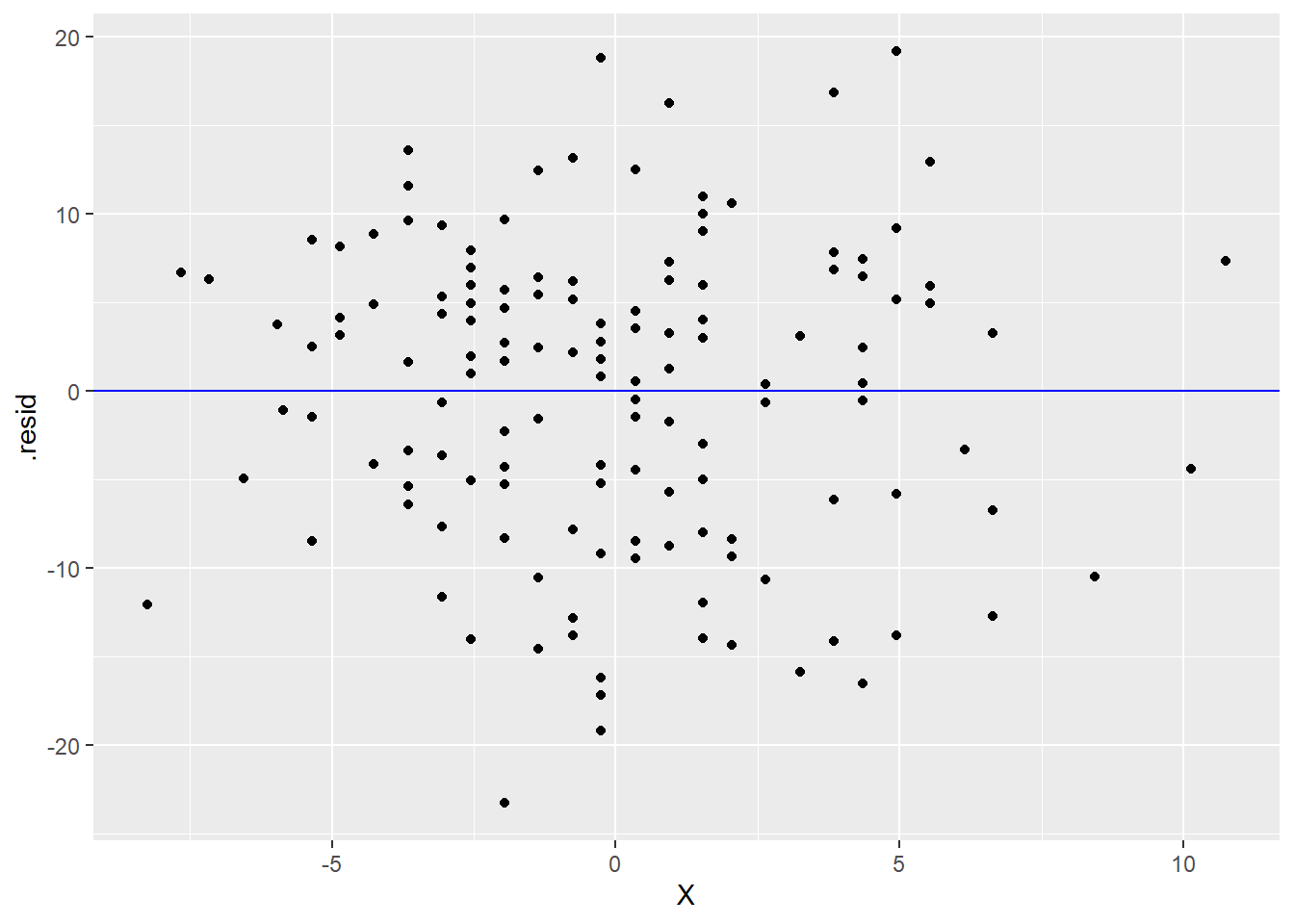
or
ggplot(YX_aug, aes(y = .std.resid, x = X)) +
geom_point() +
geom_hline(yintercept = 0, color = "blue")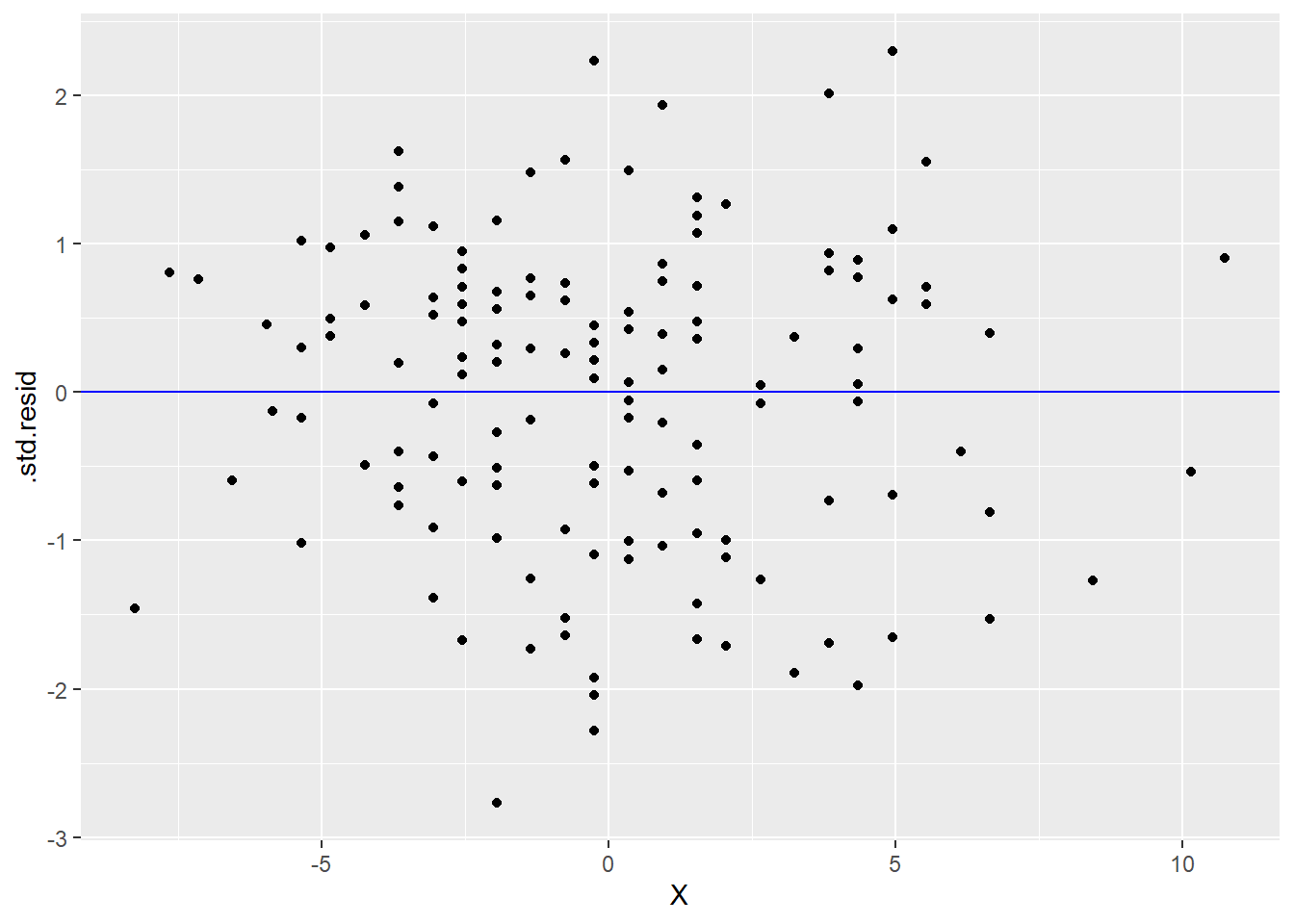
What do you see in the graphs above? Is this good or bad? What indicates in these graphs that the residuals are independent of \(X\)?
4.10.2 Using lavaan
We will also introduce you briefly to the lavaan package. While it’s totally overkill for simple regression, getting used to the syntax now will make it easier to continue to build up your confidence in using it when it will be the only tool we use.
A lavaan model is built in a similar way to lm using the tilde ~ notation. One big difference is that the model needs to be specified inside quotation marks first and assigned to a name like this:
TEMP_WIND_model <- "Y ~ X"Then we pass that model text to the sem function from lavaan:
TEMP_WIND_fit <- sem(TEMP_WIND_model, data = airquality_mc)The model is now stored as TEMP_WIND_fit. One way to learn about the model is to use the parameterEstimates function.
parameterEstimates(TEMP_WIND_fit)## lhs op rhs est se z pvalue ci.lower ci.upper
## 1 Y ~ X -1.230 0.193 -6.373 0 -1.609 -0.852
## 2 Y ~~ Y 70.337 8.042 8.746 0 54.575 86.098
## 3 X ~~ X 12.330 0.000 NA NA 12.330 12.330There is a lot of output here, and we’re not going to talk about most of it now. Focus on the est column.
You should recognize these three estimates. Explain what these numbers represent.
In particular, pay close attention to the second line. If you are hasty, you may think this is the variance of \(Y\), but that is not correct.
We can also produce the standardized estimates.
standardizedSolution(TEMP_WIND_fit)## lhs op rhs est.std se z pvalue ci.lower ci.upper
## 1 Y ~ X -0.458 0.060 -7.577 0 -0.576 -0.340
## 2 Y ~~ Y 0.790 0.055 14.273 0 0.682 0.899
## 3 X ~~ X 1.000 0.000 NA NA 1.000 1.000Again, explain these three numbers. (They are now listed in a column called est.std for “standardized estimates”.)
Verify that the second line is actually the error variance. (Hint: remember \(1 - r_{YX}^{2}\).) How do we know it’s not the standardized variance of \(Y\)? (In other words, what do you actually know to be the standardized variance of \(Y\)?)
One downside of using lavaan is that it doesn’t store the residuals, so we have no way of checking that regression assumption. For more complex models in future chapters where lavaan (or some comparable package) is the only choice, the residual independence assumption will be just that: an assumption. We must have substantive reason to believe that’s true when we specify the model.
4.11 What about intercepts?
If you are familiar with regression from another course, you may be wondering where the intercepts went. Because we mean-centered and/or standardized all the data, there were no intercepts. The regression line always passes through \((0, 0)\) for mean-centered or standardized data.
[PUT A REFERENCE HERE IF WE DECIDE TO COVER MEAN STRUCTURE IN A FUTURE CHAPTER.]